At the May 8, 2026 NBER Applications of AI in Healthcare panel, David Bradford, editor of the Wiley journal Health Economics, framed it this way: “As we move into an era where technical flaws become much harder to find, we may have to do more of what we probably always should have done a better job of, which is asking the hard question: is this really important? Is this really interesting? And not be embarrassed to say no on that basis.”1 The shorthand we use throughout this post is well-executed but not important, but the substance is this point that the AI workflow shifts conversations of acceptance and rejection to substantive issues.
An article’s importance is some combination of four things: the contribution’s marginal lift over what the field already knows; the practical reach of the insight for policy or clinical decision-making; how the finding sits against the field’s accumulated theoretical and empirical understanding; and whether the question is timely for the journal’s current portfolio. It is harder for an editor to explain than a missing identifying assumption, harder for a referee to translate into actionable suggestions, and harder for an author to learn from an email than from a conversation.
If we assume the criterion for acceptance has always centered on what the editor considers important, we approach published work as a source of data itself. Health economics has a handful of field journals with comparable archives, and each runs a portfolio that drifts across decades. The drift can help us understand how importance is defined in a field that has seen so much change.
What journals have actually published
We pull every research article from the four health-economics field journals using Crossref, supplement missing abstracts from PubMed, Semantic Scholar, and OpenAlex, and end up with 2,493 articles published 2015-2022 with usable abstract text. The four journals are Journal of Health Economics (JHE, Elsevier, since 1982), Health Economics (HE, Wiley, since 1992), American Journal of Health Economics (AJHE, Chicago / ASHEcon, since 2015), and International Journal of Health Economics and Management (IJHEM, Springer, since 2014).2 Full methodology, data-acquisition pipeline, classifier prompts, and replication code: METHODS.md.
We measure two things about each article. The first is substantive topic, by keyword match in title and abstract (managed care, maternal health, mental health, and so on). The second is contribution scope, classified by an LLM reading each abstract.
Topics drift; the drift is real
JHE has the longest archive and shows the cleanest temporal pattern.
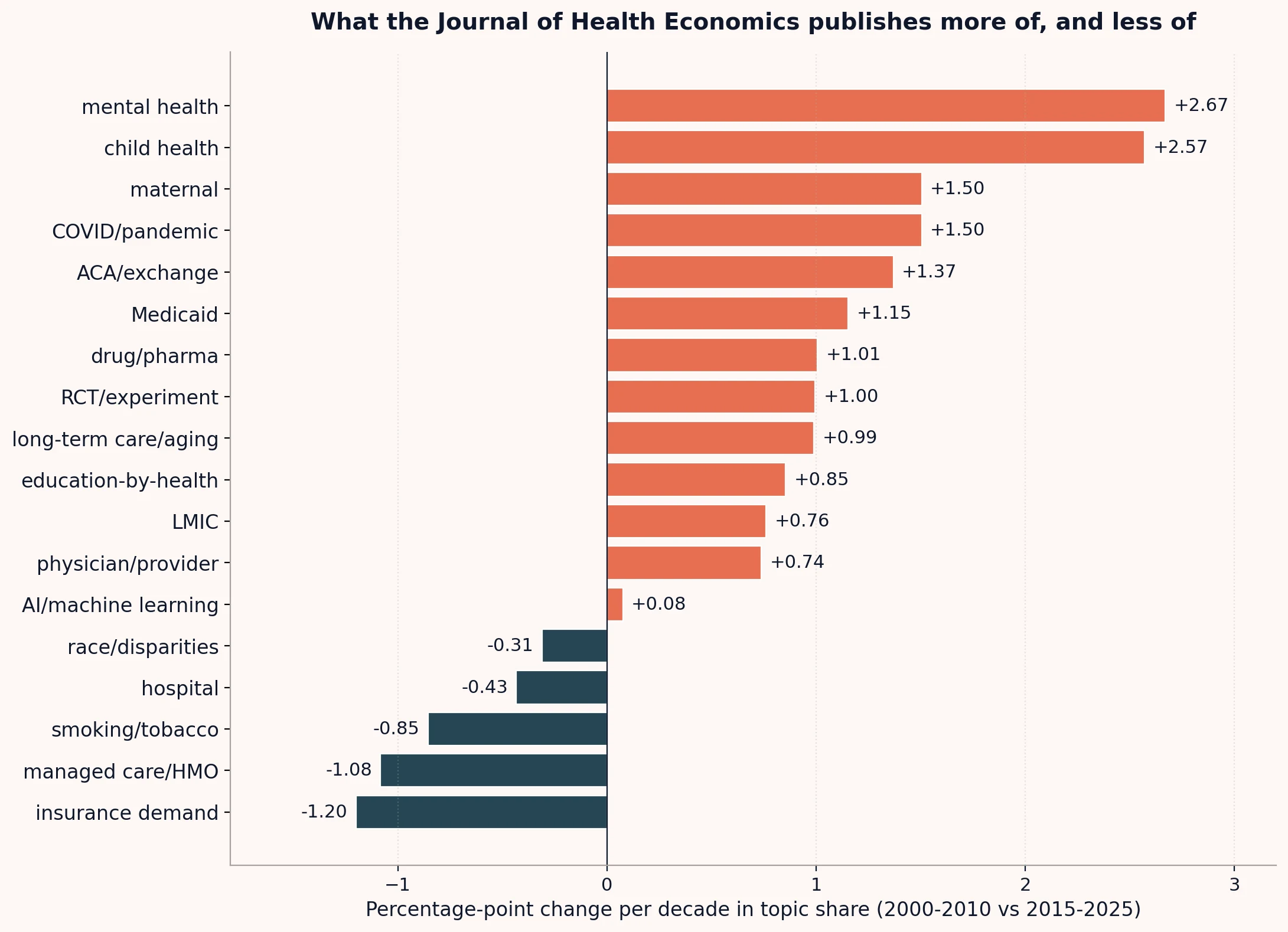
Percentage-point change per decade in JHE topic share, 2000-2010 vs 2015-2025. Source: Crossref metadata for ISSN 0167-6296, 854 research articles in 2000-2010 and 1,051 in 2015-2025. Topics tagged by keyword presence in titles. Multiple topics per article are allowed.
The journal has shifted toward mental health, child health, maternal health, and COVID-related work, and toward coverage-policy topics (ACA, Medicaid). The retreat is from the topics that dominated the 1990s and early 2000s: insurance demand, managed care, and smoking. AI and machine learning is essentially absent from JHE titles so far.
A caveat on the topic measurement: we lag what editors are doing in the present. Acceptance-to-publication runs 12-24 months in top economics journals, with the slowdown well-documented for decades.34 A paper appearing in JHE in 2024 was likely submitted in 2022 and accepted in 2022-2023. Topic distributions in publications are a lagged measure of editorial accept decisions.
Across all four field journals in the most recent decade, the topical portfolios differ in instructive ways:
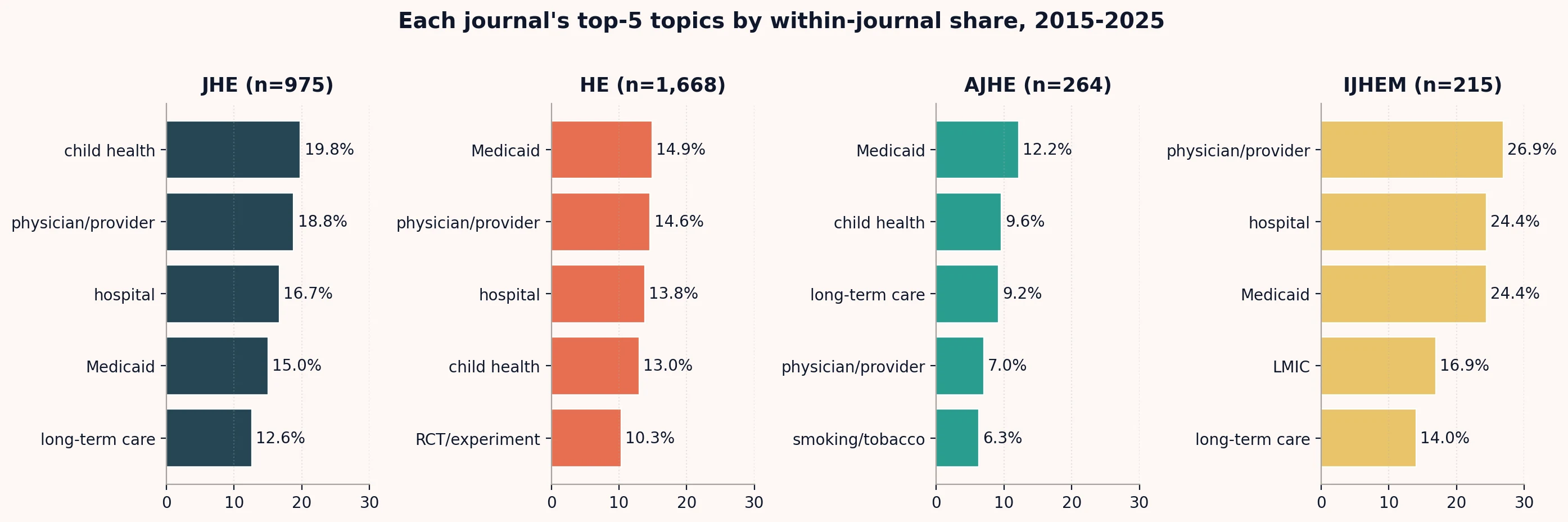
Each panel shows a single journal’s top-five topics ranked by within-journal share of articles 2015-2025. Ranking rather than raw cross-journal levels makes the portfolios comparable even though abstract-availability differences across publishers affect detection rates. IJHEM is the most concentrated portfolio (top 3 topics are over 24 percent each). AJHE includes smoking/tobacco in its top five, which the others do not. Medicaid is in the top three at every journal except JHE, where it lands fourth.
What kind of contribution
Topic tells us what a paper is about. Scope tells us what kind of contribution it makes. We can classify each abstract into one of three non-hierarchical bins based on this rubric:
| Scope | What the paper does | Signal phrases in the abstract |
|---|---|---|
| Calibration | Adds a credible estimate to an established literature. Applies a known method to a setting that fits a known template. Effect is incremental; results often consistent with prior literature. | “We apply X to Y,” “Extends to,” “Standard model,” “Consistent with prior literature,” “We estimate (existing parameter)” |
| Identification | Introduces a credible identifying strategy for a question prior work has measured noisily. The identifying variation is the lift. | “First credible quasi-experimental evidence on,” “Exploits [reform / natural experiment / IV],” “Difference-in-differences using [credible variation]” |
| Reframing | Opens or reshapes a line of inquiry. Combines causal design with new data, new method, or new question. Implications travel beyond the immediate setting. | “First credibly causal estimate of [important effect],” “Novel linkage of [data sources],” “Provides first multi-country evidence,” “Reshapes [established debate]” |
The labels are deliberately non-hierarchical. Calibration is not a lesser activity than Identification; field journals are supposed to host calibration work, and the cumulative empirical literature in any subfield rests on it. The labels name what the paper does without ranking its worth.
Three diagnostic questions a reader can apply to their own paper:
- Does the identifying variation exist before this paper?
If yes (an existing reform, an existing dataset, an existing instrument) and the paper applies it to one more setting, it lands as Calibration. If no (the paper constructs the variation, links new data, or designs the experiment), it lands as at least Identification.
- Does the answer change how someone in an adjacent subfield would frame their next paper?
If yes, at least Identification, possibly Reframing. If the answer adds to a known table of estimates, Calibration.
- Are the implications confined to one setting/policy/country, or do they generalize?
If implications generalize across health-economics subfields, and the design is credibly causal, and the data is novel or unusually well-suited, the paper lands as Reframing.
The empirical distribution of scope across the four journals:
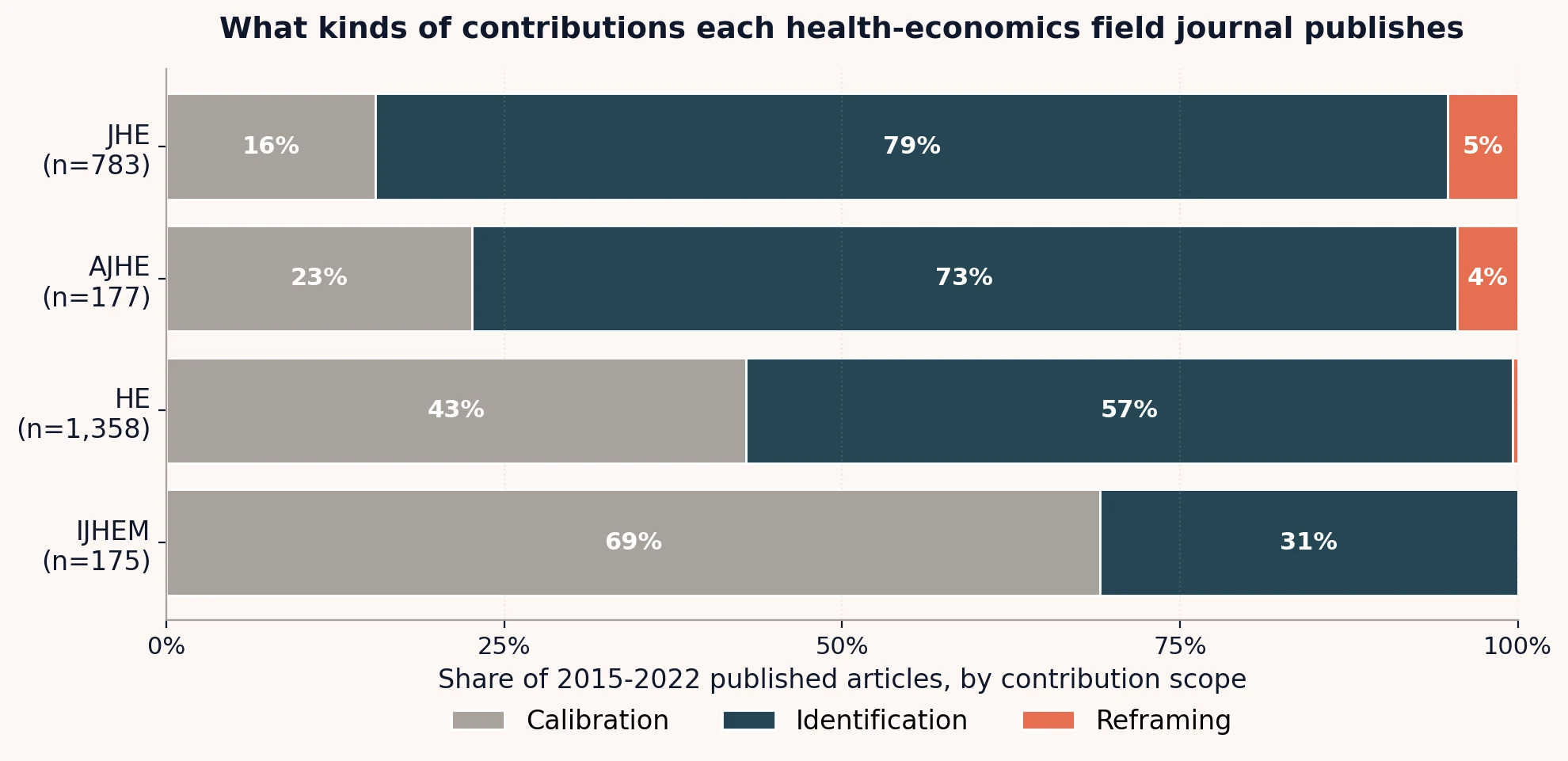
Share of 2015-2022 published articles by contribution scope, four health-economics field journals. n = 783 (JHE), 177 (AJHE), 1,358 (HE), 175 (IJHEM). Classification by an LLM reading the abstract; the abstract corpus is supplemented from PubMed, Semantic Scholar, and OpenAlex to reach 79-99 percent coverage per journal. Methodology writeup linked above.
JHE and AJHE are the Identification-heavy tier (78-84 percent of publications). HE is closer to a 50-50 split. IJHEM is Calibration-dominant. Reframing is rare everywhere and absent from the smaller journals; the field-journal selection section below explains why.
What the field actually cites
Across all four field journals over 2015-2022 (n=2,493, allowing three or more years for citation accumulation), the citation distribution by scope tells a different story than the publication distribution.
| Scope | Publication share | Citation share | Ratio | Mean cites |
|---|---|---|---|---|
| Calibration | 35% | 18% | 0.51x | 11 |
| Identification | 63% | 78% | 1.23x | 27 |
| Reframing | 2% | 5% | 2.14x | 46 |
Two facts stand out. First, Calibration papers occupy one third of journal slots and produce just under one fifth of citations. Second, the small share of Reframing work pulls more than twice its publication weight in citations.
Holding journal, year, and 18 topic fixed effects constant in an OLS regression of log(citations + 1) on scope dummies (n=2,493, R² = 0.36, HC1-robust standard errors), two findings stand out:
- Identification papers earn +91 percent more citations than Calibration papers. (95% CI [+60%, +127%], p<0.001)
- Reframing papers earn +126 percent more than Calibration papers. (95% CI [+60%, +220%], p<0.001)
This is the empirical answer to “what counts as important enough at a health-economics field journal.” Papers that build a credible identifying strategy are cited roughly twice as often as Calibration papers, and Reframing papers about twice as often again, holding topic, journal, and year constant.
The gap between Calibration’s 35-percent publication share and 18-percent citation share is the empirical signature of well-executed but not important: papers that meet the technical bar and add an estimate, but do not produce engagement proportional to their share of journal slots.
What that means when the methods floor rises
Evidence on AI’s effect on the editor’s desk has accumulated quickly. Submissions to Organization Science have risen 42 percent since the late-2022 release of ChatGPT, alongside measurable declines in writing quality; AI-generated writing accounts for nearly all of the increase.5 Across a much larger sample of 5,114 journals and 5.2 million papers, AI-assisted writing has accelerated across disciplines and countries; only about 0.1 percent of recent papers disclose AI use, and journal AI policies have not slowed adoption.6 Pandemic-era data sets the upper bound on what editorial throughput can absorb without breaking: submissions to four leading agricultural-economics journals rose 33.6 percent on a de-seasonalized annual basis from 2019 to 2020, while desk-rejection rates stayed stable and overall throughput held.7 Simulation modeling for business-school journals shows that early AI adopters initially benefit; overall acceptance rates fall sharply as load increases, with tenure-track faculty disproportionately worse off.8 Health publishing is documenting the same dynamics in medicine specifically.9 Editorial systems can absorb a roughly 30-percent surge; a doubling or tripling pushes them into capacity-rationing, where the criterion for acceptance becomes the only lever.
The implications for an applied health economist writing a 2026-2028 paper are sharper than the general AI story.
First, the Calibration tier is the one most exposed to the AI submission surge. AI-assisted authors can produce more competent Calibration work faster than they could two years ago, and that tier is where editorial capacity already over-publishes relative to engagement. If the historical gap (35 percent of slots, 18 percent of citations) compresses under capacity pressure, calibration acceptance is the natural margin to tighten.
Second, the Identification tier is where the field engages most in citations. Authors gauging what the field engages with have a clean descriptive signal: a paper whose abstract can credibly claim “first credibly causal evidence of X using Y design” is cited roughly twice as often as a paper whose abstract reads as standard application work, holding topic and venue constant.
Third, in the JHE title corpus, AI and machine learning is essentially absent (+0.08 percentage points per decade, on a base of zero). The published-topic data is two years lagged from editorial acceptance, so the early AI submissions are still in the pipeline. The interesting forward question is whether AI work follows the COVID trajectory (sudden jump, sustained share) or the managed-care trajectory (decade-long peak, then collapse).
What this does to the next generation of economists
The back-propagation is the part most worth thinking about. PhD advisors teach the criterion they think their students will be judged by. For the last twenty years, that criterion has been primarily methodological: can the student defend the identifying assumption, run the heterogeneity analysis the referee will demand, write the replication package the data-availability statement requires. The technical floor a PhD has been trained to clear is a real and useful skill, and it is becoming abundant. The skill that gates whether a paper is interesting enough to publish is the one with the least objective measure of teaching efficacy. Judging importance depends on a grounded understanding of where the field is, and it is expected to come with time and experience.
A second-year paper that is well-executed and not important is, in 2024-2025, easier to publish than a poorly-executed paper that is important. That is the old equilibrium. The new equilibrium, if the AI workflow continues to compress the technical-flaws layer, is one where the well-executed-but-not-important paper has to compete with other well-executed papers on the dimension that takes the longest to develop in any researcher.
The shift is an opportunity
AI levels the technical-flaws floor and frees bandwidth for the work that gates publishing on the dimension that actually matters: which questions are worth asking. Our companion piece on cycling through bad ideas faster makes the same point from the researcher’s side; cheaper iteration through unviable hypotheses creates room to ask bigger, bolder questions, and to discard them quickly when the evidence does not bear them out.
The applied economist preparing their next submission is the audience this matters most to. Engaging with the editors who maintain these standards, the people running the desks at the field’s flagship journals, is the work that gets us collectively closer to publishing what is actually important. The next paper is the one where this starts to matter. The next paper is yours.
Limitations
The most consequential limitation is one we cannot fully resolve: the classifier cannot cleanly separate papers that do identifying work from papers whose abstracts are written in identifying-work conventions. Abstracts using “first credibly causal” or “first to” framing land in Identification 88 percent of the time. Calibration abstracts almost never use that framing (1.5 percent rate), so authors of incremental work generally do not overclaim. But papers with genuine identification substance and modest abstracts likely get downgraded, since the classifier defaults vague abstracts toward Calibration. The main result (Identification papers earning roughly twice the citations of Calibration papers) would, if anything, be understated by misclassification in this direction.
Field journals are one tier of the health-economics publication market. Top contributions route to general-interest journals (AER, QJE, JPE, ReStud, AEJ:Applied/Policy) before or instead of field journals. The scarcity of Reframing papers (2 to 5 percent across the four journals) and the absence of the “Foundational” tier in our classification reflect selection into the field-journal market specifically, distinct from the field’s overall production of path-opening work.
Citation count is an imperfect measure of importance. A controversial paper accumulates citations for the wrong reasons. Recent papers (2020-2022) have had less time to accumulate citations regardless of quality. Year fixed effects absorb mean time trends, but within-year variance remains. Quantile regression at the median and a trim of the top 1 percent of cited papers both preserve the sign and significance of the scope premium, though the magnitude attenuates by 20-30 percent; the OLS estimates above should be read as means, not as uniform effects across the citation distribution.
Full methodology, regression specifications, robustness checks, classifier prompts, sensitivity to LLM model choice, and the complete eight-point limitations discussion live in METHODS.md on GitHub.
Replication
The Crossref pulls for all four field journals, the PubMed and Semantic Scholar and OpenAlex abstract supplementation, the topic and scope classifiers, the year-by-year and citation-weighted shares, and the figure-generation scripts are released alongside this post at github.com/dphdame/journal-topic-shares. The analysis is one-step reproducible with a single make all after pip install and an ANTHROPIC_API_KEY for the scope classifier (estimated API cost ~$6 with prompt caching, model and prompt specified in the methodology writeup). Other journals can be added by changing the ISSN at the top of the pull script.
References
- Simon, K. (2026, May 18). Practical advice for using AI in health (& other) economics research: Summary of NBER panel from May 8th 2026. Frankly, the counterfactual was worse (Substack). Writeup of moderated panel at NBER Applications of AI in Healthcare meeting, Cambridge, MA, May 8, 2026; panelists Kosali Simon, Scott Cunningham, David Bradford, and Coady Wing. https://franklythecounterfactual.substack.com/p/practical-advice-for-using-ai-in
- Crossref. (2026). Crossref REST API and journal metadata. https://api.crossref.org/journals/. Retrieved May 26, 2026 (n = 3,020 research articles in ISSN 0167-6296, 1982-2026; 4,098 in ISSN 1057-9230, 1992-2026; 296 in ISSN 2332-3493, 2015-2026; 253 in ISSN 2199-9023, 2014-2026). Abstract supplementation via NCBI E-utilities (eutils.ncbi.nlm.nih.gov), Semantic Scholar Graph API (api.semanticscholar.org), and OpenAlex (api.openalex.org), retrieved May 25-26, 2026.
- Ellison, G. (2002). The slowdown of the economics publishing process. Journal of Political Economy, 110(5), 947-993. https://doi.org/10.1086/341868
- Card, D., & DellaVigna, S. (2013). Nine facts about top journals in economics. Journal of Economic Literature, 51(1), 144-161. https://doi.org/10.1257/jel.51.1.144
- Gartenberg, C., Hasan, S., Murray, A., & Pierce, L. (2026). More versus better: Artificial intelligence, incentives, and the emerging crisis in peer review. Organization Science, 37(3). https://doi.org/10.1287/orsc.2026.ed.v37.n3
- He, Y., & Bu, Y. (2026). Academic journals’ AI policies fail to curb the surge in AI-assisted academic writing. Proceedings of the National Academy of Sciences, 123(9), e2526734123. https://doi.org/10.1073/pnas.2526734123
- Biondi, B., Barrett, C. B., Mazzocchi, M., Ando, A., Harvey, D., & Mallory, M. (2021). Journal submissions, review and editorial decision patterns during initial COVID-19 restrictions. Food Policy, 105, 102167. https://doi.org/10.1016/j.foodpol.2021.102167
- Jiang, S. (2025). Tenure under pressure: Simulating the disruptive effects of AI on academic publishing. arXiv preprint arXiv:2509.16925. https://arxiv.org/abs/2509.16925
- Arzilli, G., Di Maggio, E., De Angelis, L., Baglivo, F., Savoia, E., Privitera, G. P., & Rizzo, C. (2025). A surge of AI-driven publications: The impact on health professionals and potential mitigating solutions. Frontiers in Public Health, 13, 1680630. https://doi.org/10.3389/fpubh.2025.1680630
Cite this article
Cholette, V. (2026, May 25). Well-Executed But Not Important. Too Early To Say. https://tooearlytosay.com/research/methodology/well-executed-but-not-important/