Do state Medicaid programs that go by names like TennCare, HUSKY, MassHealth, and Cardinal Care pull in more enrollees than the ones that just call themselves “[State] Medicaid”? The closest direct empirical test is a 2024 preregistered survey experiment by McIntyre, McCrain, and Pavliv, which found that respondents under the branded names were less sure what the program was[1]. Whether that confusion shows up in cross-state behavior is what we test. The data is public, and the question sat on a shelf for years because the cost of finding out it leads nowhere was higher than the cost of leaving it there. What changes when that cost falls?
Cheap iteration looks dangerous at first. Faster cycles feel like more opportunities to miss something, more pressure to ship the first robust-looking result, more risk of blind data mining. Sit with the actual experience and the worry inverts. Cheap iteration makes it easier to walk away from a bad idea, because the sunk-cost pressure to publish whatever turns up is lower. It also makes it easier to dive deeper into a good one, because the bandwidth that used to go into data wrangling now goes into testing alternative codings, learning unfamiliar techniques, and verifying citations against primary sources.
The judgment about what is worth pursuing is what gates whether something becomes a paper, on either side of the submission[2]. A companion piece, on the editor-side of the same question, treats the published record as data to ask what "important" has actually meant.
This post is the worked example of that judgment from the researcher’s side. The branding question came off the shelf two weeks ago and ended at a null, by way of three coding rules, four model specifications, two figures’ worth of confounder diagnostics, a literature pretest of the canonical citations, and a stratified test of a published survey-experimental mechanism. None of the data was hard to get. The bandwidth the AI workflow freed up went somewhere else: into learning a name-proximity coding method we had not used before, building a reusable scoring module that did not exist when the analysis started, and ultimately into walking away from the original hypothesis. The replication archive is on GitHub.
Idea 1: just code “branded” by judgment
We can start by looking at the list of state programs, picking out the ones with consumer-facing names (Medi-Cal, MaineCare, KanCare, HUSKY, MassHealth, BadgerCare, TennCare, MO HealthNet, Apple Health, SoonerCare, about two dozen others), and calling those the branded group. Thirty-three states in. Then we run the staggered Callaway-Sant’Anna DiD on adult applications per eligible[3]. What comes back is +22% at event-time zero, with a confidence interval that comfortably excludes zero.
+22% is the kind of number that gets published. The story almost writes itself: branded states pull more applications. That runs against McIntyre’s survey-experimental finding (n = 5,807 respondents[1]), but a +22% behavioral effect would land and stay regardless.
The number would also be wrong, for two reasons. The coding rule depends on judgment calls that any two readers would code differently on a third of the borderline states. And whatever the right coding is, proper controls drive the +22% to zero. Both of those findings came out of iterating with an AI critique loop, not from the original analytical thread.
Idea 2: use a string-similarity benchmark instead
So we want a less subjective coding. The first algorithmic move is to benchmark state program names against the 2014 ACA Marketplace plan corpus using trigram-Jaccard similarity. The intuition is reasonable. If a state’s program name is similar to commercial-insurance plan names, it counts as branded. We code it up and look at the top-scoring states.
The metric has a structural flaw, and looking at the top-scoring states surfaces it immediately. The QHP corpus is saturated with “Care” and “Health” suffixes, which inflates similarity scores for state programs whose only distinctive element is a kid-program label. Georgia’s combined “Georgia Medicaid / PeachCare for Kids” scores above the threshold because of “PeachCare for Kids” matching dental and children’s QHP plans, not because of any adult-program branding. New York’s “New York State Medicaid / Child Health Plus” has the same problem. Three states score above the threshold for entirely the wrong reason.
At the iteration cost we want to operate at, this discovery is a single afternoon. Write the scoring code; look at the top-scoring states. Notice that GA and NY do not pass the smell test for “consumer-facing brand,” trace the score back to its driving trigrams, discard the benchmark. In a normal coauthor cycle, the same realization is a week of email back-and-forth and a revised draft.
Idea 3: measure distance from “Medicaid” itself
The intuition that breaks the loop is that we have been benchmarking against the wrong reference. The right benchmark is distance from the literal word “Medicaid,” not similarity to commercial exchange plans. A state’s program is branded to the extent that its name does not share trigrams with “Medicaid”, “[State Name] Medicaid”, or “Medical Assistance” (the three generic anchors the literature uses interchangeably). Higher distance, more distinctive consumer-facing brand.
The intuition pays off in an unexpected way. It produces a coding rule that turns out to be reusable beyond this analysis. The core algorithm is short:
import re
def trigrams(s: str) -> set[str]:
s = re.sub(r"[^a-z0-9 ]", " ", s.lower())
s = re.sub(r"\s+", " ", s).strip()
return {s[i:i+3] for i in range(len(s)-2)} if len(s) >= 3 else set()
def jaccard(a: set, b: set) -> float:
return len(a & b) / len(a | b) if (a and b) else 0.0
def distance_from_anchors(name: str, anchors: list[str]) -> float:
"""1 minus max trigram-Jaccard similarity against any anchor."""
t = trigrams(name)
return 1.0 - max((jaccard(t, trigrams(a)) for a in anchors), default=0.0)
For state Medicaid program names, the anchor set is ["Medicaid", f"{state_name} Medicaid", f"{state_abbr} Medicaid", "Medical Assistance"]. We score each state’s adult-program name segment against the four anchors, take the closest match, and call the state branded if the distance is at least 0.85.
Trigram-Jaccard similarity itself is not new. Broder’s 1997 MinHash work and Charikar’s 2002 rounding-algorithm paper formalized the methods that everyone uses for fuzzy string matching today[4][5]. Applied microeconomists know the family from media-slant work (Gentzkow and Shapiro 2010 on newspaper text similarity)[6] and from policy-text diffusion analyses.
What we’re adding here is the application: a principled, replicable distance-based coding rule for state Medicaid branding, where previous empirical work has used judgment, ad hoc lists, or implicit hand-coding without reporting reliability. Marzilli Ericson and Starc on the Massachusetts exchange examined how standardization shifted brand market shares[7]; their analysis did not formalize a brand-versus-generic coding rule from program names directly.
The technique generalizes. SNAP rebrands (Food Stamps to SNAP), TANF state programs, CHIP program names, ACA Marketplace plans, or any setting where a researcher codes ambiguous categorical treatments from program names can use the same scoring rule. The reusable module is in the GitHub repo.
![Two-column horizontal bar chart titled "State Medicaid program names, ranked by distance from Medicaid." Each row shows a state abbreviation, the adult-program name, and a bar whose length encodes distance from the generic-anchor set. Bars are colored coral for branded states (distance ≥ 0.85, including HealthChoices, Turquoise Care, Apple Health, BadgerCare Plus, HUSKY Health, Diamond State Health Plan, Cardinal Care, KanCare, MassHealth, TennCare), light navy for borderline states (0.50–0.85, including MaineCare, Medi-Cal, Oregon Health Plan, Health First Colorado, Healthy Louisiana, MinnesotaCare), and muted gray for states at or near zero distance (the [State] Medicaid generics).](/images/methodology/cycling-through-bad-ideas-faster/fig1_naming_proximity_ranking.webp)
Each state’s adult program name scored on trigram-Jaccard distance from the generic-anchor set. The 0.85 threshold (dashed line) separates 22 distinctively-named states from 29 generic ones. Medi-Cal and MaineCare sit in the borderline zone (0.80, 0.81); they share enough trigrams with generic anchors to be ambiguous, which matches the reader’s intuition that those names are partway between branded and generic.
22 states come out as branded under this rule, with 6 in-window staggered cohorts (Kansas 2013, New Mexico 2014, Iowa 2016, Nebraska 2017, Arkansas 2022, Virginia 2023). The rest adopted their brands before the panel window opens in 2010 and contribute pre-sample variation only.
Now we have a defensible coding. What does the +22% look like under proper controls?
From +22% to a bounded null
Re-running the staggered DiD on the new coding produces a much smaller positive coefficient at event-time zero: +1.2 percentage points on log enrollment growth, just barely significant. That is the starting point for the controls ladder. Anyone reading a Medicaid DiD paper in the 2024-2026 cohort wants to know which moving parts the coefficient is sensitive to.
So +1.2, fragile. What checks should we run? The standard ones for a state-panel DiD: regional shock heterogeneity, then expansion-cohort heterogeneity, then political controls, then renewal-infrastructure controls. We add each layer and watch the point estimate.
First layer is HHS region × year fixed effects, to absorb regional Unwinding heterogeneity. The CI widens; the point estimate barely moves. Still positive, still fragile. Second layer is expansion-cohort × year fixed effects. And the sign flips. Once states in the same ACA expansion cohort share year-specific shocks, the branding coefficient drops to −2.2 percentage points and the CI swallows zero.
![Forest plot with seven rows, one per model specification (M1 through M7), each showing a point estimate and 95% confidence interval for the branding effect at event-time zero on log-enrollment growth. M1 (state and year fixed effects only) shows +0.012 with the CI just excluding zero, coral colored. M2 (adding HHS region × year) shows +0.013 with a much wider CI that crosses zero. M3 (adding expansion-cohort × year) flips to −0.022, dark navy, CI [-0.059, +0.014]. M4 through M7 stay at approximately −0.022 with CI widths around ±0.044 as additional controls for marketplace structure, governor party, presumptive eligibility, ex parte renewal rate, and procedural disenrollment rate are added in turn.](/images/methodology/cycling-through-bad-ideas-faster/fig2_controls_ladder.webp)
Branding’s coefficient on log-enrollment growth at event-time zero across seven control specifications. The expansion-cohort × year fixed effects (M3) absorb the entire apparent positive effect; adding marketplace structure, political variables, and renewal-infrastructure controls in M4-M7 leaves the point estimate at approximately −0.022 with a 95% CI of roughly [−6.6%, +2.1%]. Cluster-robust standard errors.
Why does that second layer do so much work? Of the six in-window branded cohorts, three (New Mexico 2014, Iowa 2014, Arkansas 2014) adopted ACA expansion in 2014. Two more (Nebraska 2020, Virginia 2019) expanded later but still during the panel window. Only Kansas, which has not expanded, is a non-expander in the branded cohort. Brand timing and expansion timing are correlated. Without controls for the latter, the brand variable absorbs the former’s enrollment trajectory. A careful seminar question catches this in the first five minutes.
The fully controlled M7 specification still has one residual concern we want to flag and respect. The pre-period coefficient at event-time minus three is significant at the five percent level, suggesting that some cohort heterogeneity escapes the expansion-cohort × year structure. The bounded coefficient is a bound under the assumption that the residual pre-trend does not artificially inflate the identified zero. With six single-state cohorts, the design will not push further on this question. The next step is to read what the bound tells us, and what it doesn’t.
Reading the bounded coefficient
What the controlled bound tells us is what is ruled out, given the data. Anything larger than about 6.6 percentage points of enrollment loss or about 2.1 percentage points of enrollment gain would be ruled out, conditional on the controls. The interesting follow-up question is whether the data should have shown a behavioral effect at all.
The McIntyre mechanism is the place to look. If state-specific names create recognition confusion (as their survey experiment finds), then in states where enrollees actually have to do something to renew (states with low ex parte renewal rates, where the recognition channel can fire), we should see worse retention in branded states than in generic ones. We stratify the controlled model on the cumulative ex parte renewal rate from the CMS State Medicaid and CHIP Eligibility Processing Data, computed over the 19-month Unwinding window from March 2023 through September 2024. The stratification is severely underpowered (only two in-window branded cohorts fall in the low-ex-parte stratum), so the result does not carry weight. For what it is worth, the low-ex-parte stratum has a positive point estimate at event-time zero, opposite the direction McIntyre’s mechanism would predict if it operates in behavior.
That stratification does not carry weight. The substantive check is whether branded states differ systematically from unbranded ones on the renewal-infrastructure variables that would offset confusion.
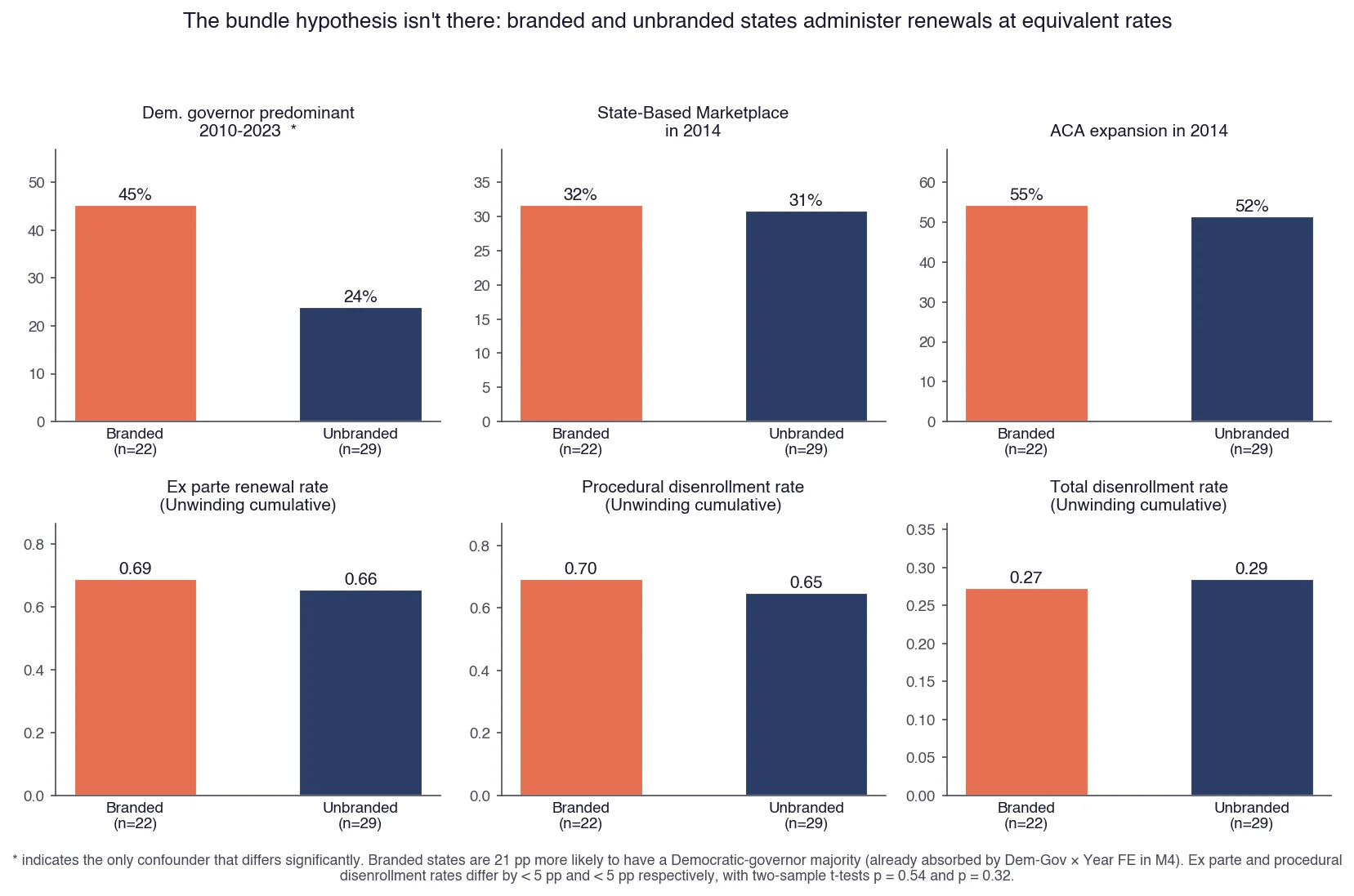
Branded and unbranded states compared on six potential confounders. Only governor party clusters significantly with branding (already absorbed by Dem-Governor × Year fixed effects in M4 onward). On the renewal-infrastructure variables that would mechanically mute the McIntyre recognition channel (ex parte renewal rate and procedural disenrollment rate), the two groups are statistically indistinguishable. The bundle that would explain away the null is absent.
If branded states had administrative infrastructure that mechanically muted the McIntyre recognition channel (higher ex parte renewal rates, lower procedural disenrollment rates), a controlled null would be consistent with a real behavioral effect that the infrastructure offsets. That is the objection a referee raises, and the objection that demands a separate check. The data say the offsetting bundle is not there. On the renewal-infrastructure variables that would mechanically mute the recognition channel, branded and unbranded states are statistically indistinguishable.
The bound is what we can claim with the design we have. What we cannot claim: that branding never matters anywhere, that the McIntyre survey finding is wrong about attitudes, or that a pure name-change experiment would yield the same null. Cross-state observational data is the wrong design for the cleanest answer. A within-state synthetic control on a pure rebrand (Cardinal Care 2023 is the cleanest candidate) is the next workstream.
Walking away, or diving deeper
That is the worked example. The decision in any analytical thread is binary. Walk away from this idea because the data does not support it. Dive deeper because the data does. Both directions require bandwidth that the data-wrangling and iteration overhead of pre-AI workflows often consumed before the judgment call could even be made.
The branding analysis walked away from two ideas and dived deeper into one. Idea 1 (judgment-coded branding) and Idea 2 (QHP-corpus benchmark) both got reported, run, examined, and discarded. Each discard was an afternoon rather than a week. Diving deeper happened once. Idea 3 (distance-from-Medicaid coding) led to a controls ladder, a bundle-correlation diagnostic, and a stratification test against a published survey-experimental mechanism. Each of those moves is referee-standard for an applied health economics paper. What AI changed was the elapsed time between deciding the dive was worth taking and reporting the result.
The byproduct that is easy to miss is what the iteration produces in the failed direction. The distance-from-anchor scoring rule did not exist at the start of the analysis. It emerged because the first algorithmic coding failed in a specific direction, the intuition about why it failed pointed toward a different reference target, and the iteration cost of testing the new direction was low enough to write the module. In a slower workflow the QHP-corpus failure would have prompted a return to judgment coding. Cheap iteration changes what techniques researchers build, in addition to changing which specifications they run.
Two verification failures from this iteration loop
Before closing, two verification failures the iteration loop produced are worth flagging. Both were caught by separate verification passes.
A subagent verifying citations for this article surfaced that an earlier draft had attributed Aizer (2007), “Public Health Insurance, Program Take-up, and Child Health,” to the Journal of Public Economics. The paper is published in Review of Economics and Statistics, 89(3):400–415. The wrong-journal attribution would have appeared in the reference list and embarrassed the author at any reader who pulled the citation. The verification subagent flagged it because the verification protocol fetches the actual source rather than generating the citation from memory.
An earlier verification round in a different session attributed authorship of a Constantin et al. paper to “Constantin/Kenney/Simon/Chua” when the actual authors are Constantin/Chua/McCullough. The verification memo’s tight formatting carried false authority. The AI was confidently wrong about names it had never actually fetched. The discipline that catches these errors is treating verification memos as inputs to verify against primary sources, never as authoritative outputs. Citation verification is the most consequential place AI fails confidently, and the most important place to require a separate verification pass.
We can see that AI is unreliable in known directions: verbatim quotes from inaccessible sources, citation metadata from memory, confidently-formatted memos that report names the system never looked up. The iteration cost of building separate verification passes against those known failure modes is low enough that solo researchers should build the passes and treat the AI outputs as input artifacts to check.
The replication archive
The reusable byproduct from this analysis is on GitHub. The replication archive at github.com/dphdame/medicaid-branding-naming-proximity contains:
naming_proximity.py: the standalone reusable scoring modulestate_treatment_v1.csv,v2.csv,v3.csv: three treatment files representing the judgment, QHP-Jaccard, and distance-from-Medicaid codingsstate_unwinding_metrics.csv: cumulative ex parte and procedural disenrollment rates by state from CMS data.medicaid.gov, computed over March 2023 through September 2024run_controlled_did.R: the R script that produces the M1 through M7 controls ladder- A README documenting variable definitions, data sources, and the exact steps to reproduce the figures shown above
Anyone working on coding ambiguous categorical treatments from program names is welcome to lift the scoring module directly. The Medicaid-specific treatment files matter only for researchers working on Medicaid program identity, but the coding rule generalizes: SNAP rebrands (Food Stamps to SNAP), TANF state programs, CHIP program names, ACA Marketplace plans, or any setting where a researcher needs to score string distance from a generic reference.
References
[1] McIntyre, A., McCrain, J., & Pavliv, D. (2024). Medicaid by any other name? Investigating malleability of partisan attitudes toward the public program. Journal of Health Politics, Policy and Law, 49(3), 451–471. https://doi.org/10.1215/03616878-11066320
[2] Cunningham, S., & Simon, K. (2026, May 20). What a panel of economists said about AI in the production of research. Scott’s Mixtape Substack. Writeup of moderated panel at NBER Applications of AI in Healthcare meeting, Cambridge, MA, May 8, 2026; panelists Kosali Simon, Scott Cunningham, David Bradford, and Coady Wing. https://causalinf.substack.com/p/what-a-panel-of-economists-said-about
[3] Callaway, B., & Sant’Anna, P. H. C. (2021). Difference-in-differences with multiple time periods. Journal of Econometrics, 225(2), 200–230. https://doi.org/10.1016/j.jeconom.2020.12.001
[4] Broder, A. Z. (1997). On the resemblance and containment of documents. In Proceedings of the Compression and Complexity of Sequences 1997 (pp. 21–29). IEEE Computer Society. https://doi.org/10.1109/SEQUEN.1997.666900
[5] Charikar, M. S. (2002). Similarity estimation techniques from rounding algorithms. In Proceedings of the Thirty-Fourth Annual ACM Symposium on Theory of Computing (pp. 380–388). ACM. https://doi.org/10.1145/509907.509965
[6] Gentzkow, M., & Shapiro, J. M. (2010). What drives media slant? Evidence from U.S. daily newspapers. Econometrica, 78(1), 35–71. https://doi.org/10.3982/ECTA7195
[7] Marzilli Ericson, K. M., & Starc, A. (2016). How product standardization affects choice: Evidence from the Massachusetts Health Insurance Exchange. Journal of Health Economics, 50, 71–85. https://doi.org/10.1016/j.jhealeco.2016.09.005
Cite this article
Cholette, V. (2026, May 23). Cycling Through Bad Ideas Faster: A Medicaid Branding Worked Example. Too Early To Say. https://tooearlytosay.com/research/methodology/cycling-through-bad-ideas-faster/