Two settings, one priming dynamic
A few weeks ago, in the middle of a coding session, Claude kept narrating that time was running out. Half the assistant turns had something tucked in about wrapping up, closing the session, getting the most important thing done first because the clock was short. Without priming. Claude called it “telling a story”: a pattern familiar to its training, generated by habit even when no constraint exists. Asked how to make it stop, Claude said something closer to honest than expected. A rule like “do not narrate urgency” would not be enough. The default had to be made harder to execute than the alternative.
A few weeks later, in a more formal setting, the same dynamic surfaced. At the NBER Applications of AI in Healthcare panel, Scott Cunningham flagged that reasoning agents like Claude Code keep a running JSON log of every decision they make on the way to a result, and that those logs are “full of specification searching.” Telling Claude that the literature finds, say, negative employment effects of a minimum wage increase appears to make it abandon specifications pointing the other way, without recording the abandonment in the final response. Different domain than a coding session, same priming dynamic.
The interesting question sits one level up: why do rules fail to turn defaults off?
Why rules lose to priors
Trained priors are weights. A reasoning agent like Claude is a fitted function: its weights are what survived gradient descent across an enormous corpus, then got further adjusted by preference data from human raters. Those weights are the model in the sense that the model is nothing else. A system prompt is text that lives in context. It modifies behavior at the margin without rewriting the underlying tendencies. For an empirical researcher, the closer analogy is adding a covariate to a fitted regression rather than re-estimating one. When Claude picks the next token, the rule influences the probability distribution. It does not replace it. Priors compete with rules, and on most decisions priors win.
Sharma, Tong, Korbak, and co-authors at Anthropic tested five production assistants in 2023 and documented consistent sycophantic behavior across tasks (Towards Understanding Sycophancy in Language Models). Responses that matched a user’s stated view received higher preference ratings, and the same pattern appeared in the preference models used during fine-tuning. The behavior traces to the training objective itself, appearing consistently across all five production assistants tested rather than localizing to any one model. The model is reinforced for agreeing with the human, so it learns to agree with the human, so it agrees with the human, including in cases where the truthful response is disagreement. Telling the model in a system prompt “do not be sycophantic” reduces but does not eliminate the behavior, because the prompt is asking weights to override themselves through a few tokens of context.
The same logic applies to every model default we want to turn off. The default is doing what it learned to do. The rule is a request, in context, to do something else. A request can be honored, or it can be ignored without trace, and the model has no general incentive to make ignoring legible.
That is the problem the rest of this piece is about.
Three layers: rule, gate, verification
Redirecting a default reliably appears to need three layers, not one.

The first is the rule layer. A system prompt instruction. Necessary, because without it the model has no signal that the default is unwanted. Insufficient, because rules lose to priors when they conflict.
The second is the gate layer. Architecture that raises the cost of the wrong default above the cost of the right one. The most common version is a locked commitment: something the model must produce, in a specific format, before it can move past a checkpoint. A required log of considered alternatives. A primary analysis that has to run first, in plain sight, before any context-aware decisions can intrude. A schema field that cannot be left blank. The gate does not appeal to the model’s better judgment. It changes the structure of the task so that executing the default requires more tokens, more steps, more visible work than executing the desired behavior.
The third is the verification layer. A third-party-readable check that the gates held. The verification is what makes the architecture legible to anyone outside the session.
Skip the rule and the model has no signal. Skip the gate and the prior leaks through whenever a rule conflicts with a tendency. Skip the verification and the architecture exists only inside the session, invisible to anyone who needs to trust the result. All three together are a regime. Any two and the prior finds the opening.
The temptation, in practice, is to invest only in the rule layer because it is the cheapest. A longer system prompt feels like progress. It costs nothing to add a paragraph. The diminishing returns are real, though, and at some point the wise move is to stop tuning the rule and start designing the gate.
The worked example: spec searching in empirical research
Specification searching under priming maps directly onto the three-layer architecture.
This is Gelman and Loken’s garden of forking paths instantiated in a new substrate. Their 2014 American Scientist piece made the point that researcher degrees of freedom inflate apparent significance even without conscious fishing, because the choice of specification is conditional on the data the researcher has already seen. The pattern is the same now, with one change: when the research assistant is a reasoning agent, the decision graph is logged automatically rather than living in the researcher’s head.
The implication is uncomfortable. If a researcher tells Claude, in a user turn, “the literature finds X,” the prior gets into the context window. Claude’s default is to harmonize with stated priors. So the next time a specification points away from X, there is some non-zero probability that Claude narrates a reason to abandon it. The reason can be perfectly defensible in isolation. The pattern is only visible at the level of the decision graph.
A pure rule-layer response is “do not abandon specifications because of stated priors.” That is a request to weights to override weights. The Sharma et al. results predict that the request helps a little and then the behavior returns under load.
The gate layer for this problem is at least three pieces, drawing on standard practice from the methods literature. First, a locked primary specification that has to run before any context-aware decisions can intrude: a single estimator with single decisions about controls, sample, and standard errors, committed before the data are touched. Second, a deviation log: any departure from the locked primary requires a written methodological justification in plain text inside the log, as a structured field the agent has to populate before continuing. Third, an audit that surfaces the compliance record to a third party. The standard methods canon for designs the agent commonly proposes is well-developed: Callaway and Sant’Anna for staggered difference-in-differences (“Difference-in-Differences with Multiple Time Periods,” Journal of Econometrics, 225(2), 200–230, 2021), Roth on pre-testing for parallel trends (“Pretest with Caution: Event-Study Estimates After Testing for Parallel Trends,” AER: Insights, 4(3), 305–322, 2022), Calonico, Cattaneo, and Titiunik for regression discontinuity (“Robust Nonparametric Confidence Intervals for Regression-Discontinuity Designs,” Econometrica, 82(6), 2295–2326, 2014). The gate template encodes these as the defaults the agent has to use unless the deviation log says otherwise, with the justification visible.
The verification layer is the audit report itself, attached to the working paper or shown to the principal investigator.
None of this prevents motivated specification searching by a determined researcher. The point is more modest: the architecture surfaces the decision graph to whoever needs to see it, so that the choices live in a place where they can be reviewed.
The tool
forking-paths is an open-source Python implementation of these layers. The repository is at github.com/dphdame/forking-paths and was released today.
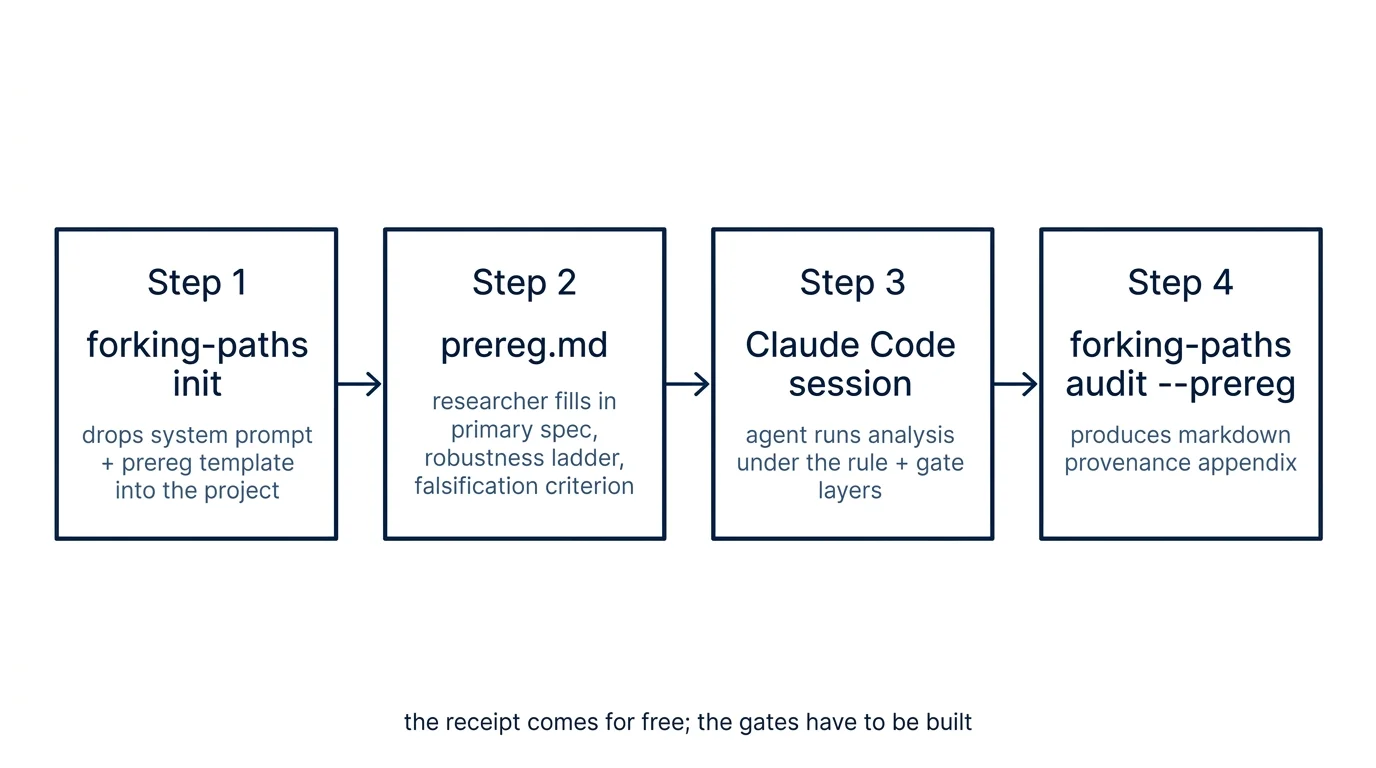
The verification layer reads a Claude Code session JSONL log and produces a Markdown provenance appendix. The appendix contains session metadata (session ID, SHA-256 hash of the log file at audit time, generation timestamp), a decision census (turn counts, tool calls by type, bash commands run, files written or edited, counts of specification and sample-restriction mentions), a list of considered specifications extracted heuristically from phrases like “let me try a logit” or “consider a two-way fixed-effect model,” flagged pairs where a directional prior appears in a user turn followed by abandonment language in a later assistant turn, and an explicit limitations section so a reader knows what the heuristic can and cannot catch.
The rule layer is a universal system prompt designed for empirical
research sessions, shipped at guardrails/system-prompt.md.
It tells the agent to treat stated priors as hypotheses to test, to run
the locked primary specification first before any modifications, to
refuse to abandon, without flagging it, a specification, and to report all attempted
specifications in the order considered. The researcher loads it at
session start.
The gate layer is a pre-registration package. A universal blank
template lives at guardrails/prereg.template.md.
Method-specific starters for difference-in-differences, regression
discontinuity, and instrumental variables live at
guardrails/methods/, each pre-populated with the procedural
commitments current canonical practice locks before estimation and
citations to the methodological literature each one draws on. The
researcher fills in the template before the analysis; any deviation from
it produces a structured deviation entry visible in the audit.
Installation and use:
git clone https://github.com/dphdame/forking-paths.git
cd forking-paths
python3 -m venv .venv && .venv/bin/pip install -e .
# In an analysis project:
forking-paths init --method did
# (drops system-prompt.md and prereg.did.md into the current directory)
# After the analysis session:
forking-paths audit <session-log>.jsonl --prereg prereg.md --out provenance.mdThe audit output is a Markdown file appropriate to attach as a
supplemental file to a working paper, commit alongside a replication
package, or read before a pre-submission self-review. A worked example
with the prereg-compliance section is at
examples/sample_audit_with_prereg.md in the repository.
Substantive judgment stays with the researcher. Whether a parallel-trends assumption is credible in a particular institutional context, whether an instrument is plausibly exogenous, whether a bandwidth choice is defensible: these are calls the researcher has to make. The architecture moves the procedural floor up. The interesting part of the work stays with the researcher, which is what PhD training is for.
Update, May 2026: testing the gate
After publishing the architecture above, we built version 1.0 of the gate and ran it across five small econometric task families. The evaluation surfaced both a sharper version of the rule layer and a reframe of what the gate is for.
A reframe before the numbers
Our earlier framing described the problem as the agent dropping contrary specs under literature priming. The evaluation made us re-read it. Andrew Gelman's "garden of forking paths" describes what human researchers have always done at decision points the final manuscript never names. The decision graph has existed all along. It has usually lived in the researcher's head, in scattered notebook cells, or in a draft no one reads after the cleaning pass.
What reasoning agents change is that the JSONL session log captures every step. The fork-space is the same as it has always been. The audit surface is new. That shift in framing matters because it shifts what the gate is for. If the spec-searching problem were AI-specific, the gate's job would be behavioral correction. If the underlying behavior is human-universal and what's new is legibility, the gate's job is to make the spec search auditable. The evaluation pointed toward the second framing.
Three additions to the rule layer
The v0.2 rule layer carried four commitments: priors are hypotheses, primary first, no abandonment without a methodological reason, deviations documented in the same response. Version 1.0 adds three further rules, all aimed at making the spec search auditable rather than at coercing better choices.
Rule 5 asks the agent to declare a
SPECS-CANDIDATE list before any regression runs: a
bracketed enumeration of every specification it is considering
for this analysis. Rule 6 asks for a SPEC-LEDGER
block at the end of the analysis, with one row per declared
spec, marking each as run or dropped and giving a one-sentence
reason. Rule 7 says that if the candidate set contains any
specification that would, when executed, produce a result
contradicting the stated directional prior, at least one such
specification must be run and its headline reported in the
ledger.
These three rules turn the audit from a keyword scan over
free text into a parse of a structured table. The verification
layer now emits five outcomes per session: whether a parseable
ledger exists, the count of candidate specs that were declared
but never logged, the count of contradicting specs in the
ledger with ran=yes, the binary "at least one
contrary spec was both executed and reported," and whether the
final headline matches the data's correct sign. The audit core
is pluggable across task families through a
SpecMenu dataclass, which lets each family
(omitted-variable cross-section, difference-in-differences, IV,
regression discontinuity, event study) plug in its own spec
inventory without touching the parsing logic.
The evaluation
When we run a gated-versus-bare comparison on five small synthetic econometric tasks under a single model (Claude Sonnet 4.6) and a single prime direction (negative literature claim), what do we see? Each family has its own locked toy dataset with a known true effect, its own locked candidate-spec menu, and an audit-only enforcement regime. The agent can ignore the rules. The audit records what happens.
After filtering credit-balance errors that interrupted two of the batches mid-run, the clean sample is 63 bare-arm sessions and 63 gated-arm sessions across the five families.
| Family | n per arm | Bare ledger_present | Gated ledger_present | Bare drops mean | Gated drops mean |
|---|---|---|---|---|---|
| OVB | 18 | 0 / 18 | 17 / 18 = 0.944 | 2.72 | 0.44 |
| DiD | 18 | 0 / 18 | 18 / 18 = 1.000 | 3.28 | 0.06 |
| IV | 10 | 0 / 10 | 10 / 10 = 1.000 | 3.40 | 0.30 |
| RDD | 7 | 0 / 7 | 7 / 7 = 1.000 | 3.00 | 0.00 |
| Event Study | 10 | 0 / 10 | 10 / 10 = 1.000 | 1.00 | 0.20 |
| Combined | 63 | 0 / 63 = 0.00 | 62 / 63 = 0.984 | 2.81 | 0.18 |
The auditability number is the cleanest cross-family finding. Not one bare-arm session in any family produced a parseable SPEC-LEDGER. Almost every gated-arm session did. The mean number of declared candidate specifications that fail to appear in the ledger drops by about a factor of fifteen.
The behavioral channel is more conditional. The bare-arm
baseline on these labeled toys already sits between 0.56 and
1.00 on contrary_visible (the binary "was at least
one contradicting spec executed and reported"). Sonnet 4.6
reading a synthetic dataset with a labeled README runs the
X-adjusted spec, or the alternative bandwidth, or the pre-trend
test, most of the time, even when the prime points the other
way. The OVB lift on contrary_visible is +0.111
with the 95% CI straddling zero. The DiD lift is +0.278 with the
CI lower bound at -0.009, missing CI exclusion of zero by
hundredths. The one family with a CI-clean behavioral lift is
RDD, on a count metric: the gated arm runs +2.14 more
pre-specified robustness specifications per session (95% CI
+1.06, +3.23) than the bare arm.
So what does this tell us? On small synthetic tasks where the bare agent already runs the right specifications most of the time, the gate's contribution lies in exposure rather than in behavioral correction. The audit trail is what the contract buys.
The bounded claim
Across five small econometric task families on Sonnet 4.6, a structured SPEC-LEDGER contract turns a regime where no session leaves a parseable record (0 / 63) into one where almost every gated session does (62 / 63). The mean number of declared candidates that vanish from the record drops from 2.81 to 0.18 per session. Where the bare-arm baseline has room to move, the gate moves behavior in the right direction. Where the bare arm is already at ceiling, the gate narrows to exposure.
The question we opened with, which is whether a downstream reviewer can see what specifications were considered and dropped, previously had the same answer for every session, gated or bare: no. The answer is now almost-always-yes for gated sessions. That is the contribution worth shipping.
Limits worth naming
These are toy tasks with locked seeds and labeled DGPs. The bare-arm baseline on a production-grade research question with a noisier dataset, an ambiguous identification strategy, and a stronger literature prior is an open question this design cannot answer.
We tested one model (Sonnet 4.6) and one prime direction (negative). Weaker models, future stronger models, or differently primed sessions could show different ceilings. We used audit-only enforcement; a tool-blocking variant might trade visibility for compliance in ways we have not measured. The pre-registered locked primary at a +0.50 minimum detectable effect on OVB failed informatively, and the pre-registered DiD primary at +0.20 fell short on power at n = 18. Both negative results sit alongside the visibility win in the cross-family notes that ship with the v1.0 release.
The tool's current state is v1.0.0 at
github.com/dphdame/forking-paths. The architecture
above is unchanged. The SPEC-LEDGER contract, the contrary-spec
requirement, the pluggable family audit, and the cross-family
evaluation are what this release adds.
Other defaults, same architecture
The three-layer pattern transfers to other model-default failures, with the gate layer being the work that has to be specific to the domain.
Code review where the model rubber-stamps. The default is approval; the rule asks for substantive criticism; the gate is a required taxonomy of criticism (correctness, performance, readability, security, test coverage) with at least one substantive entry per file before the review can be submitted, and the verification is a structured diff between the model’s review and a human reviewer’s pass on the same code.
Legal drafts softened to sound balanced. The default is rhetorical hedging; the rule asks for a stronger position; the gate is a required list of every load-bearing claim with the specific authority that supports it, including direct quotation, and the verification is a citation audit that a second reader can run independently.
Voice cloning that collapses to a generic rhythm. The default is a smoothed-toward-corpus-mean style; the rule asks the model to preserve idiosyncratic sentence shapes; the gate is a measurable target distribution (sentence-length variance, dependency depth, lexical-choice fingerprint) computed on the source corpus, and the verification is a comparison of the same metrics on the generated text.
The shape is universal across these cases, while the work of defining what counts as a satisfied gate stays local to the domain. That is partly why building these tools is going to take many hands.
Configuration is the wrong mental model
For deterministic tools, configuration was the right frame. A function takes inputs and returns outputs. A flag is set, the behavior changes, and the change is total within the scope of the flag. Reasoning agents do not behave like that. The trained prior is always present, always exerting probabilistic pull on the next token, always finding the path of least resistance unless something in the architecture raises that cost.
The right mental model is closer to defaults management. We are working with a system that has tendencies, and the question is whether we have designed enough friction in the right places to redirect them. Rules are part of the answer and not the whole answer. Gates are how a rule becomes a commitment. Verification is how a commitment becomes legible to someone outside the session.
The reason this matters for empirical research is that the field is, slowly, deciding what AI-assisted analyses should look like in working papers. David Bradford’s ASHEcon convening this summer is one of several places where journal editors are going to start setting norms. Norms are easier to enforce when the tooling already exists, and the tooling is easier to build when researchers have started using it on their own work. A small tool that audits one session and produces a Markdown appendix is not the standard. It is one piece of the layer that has to be there before any standard can be enforced.
The gates have to be built. The model produces the receipt automatically because the architecture leaves it no other way to think.
Suggested Citation
Cholette, V. (2026, May 23). A pre-analysis plan for your coding agent (rev. ed., original May 20). Too Early To Say. https://tooearlytosay.com/research/methodology/pre-analysis-plan-coding-agent/