The chore we keep doing by hand
Let’s say we’re about to write the methods section of a paper that uses honest DiD. Maybe we last read about it two years ago, maybe we’ve never used it before. The work is the same in both cases: we want to ground the methods section in something more than a Google Scholar search ordered by citation count. Three things, in roughly this order.
First, the seminal papers. Which paper established the specific bound we are about to use? Which paper introduced the broader framework? When we cite “honest DiD,” which DOI carries the result we are reaching for?
Second, the current authors. Who is working in this method family right now? If we want a referee or a co-author, or just a sense of who reads the work that gets done here, the field has a roster and we should be able to see it.
Third, the most recent applications. What has been published in the last two or three years that uses this method? An applied paper from last quarter is often a better template than the seminal paper itself, because it shows the implementation choices reviewers expect now.
What do we usually do? Find someone’s pillar post on the method and walk its references. That works once. It biases hard to the post-author’s reading. It goes stale within a year. The alternative is Connected Papers or ResearchRabbit, generic co-citation graphs that don’t know what method any of those papers uses, who established what, or what’s recent in a substantive sense. We end up squinting at a node cloud and inferring “method family” from titles.
New to Claude Code skills? The setup guide covers installation and first invocation.
What we want is a citation network that knows what method each paper uses, who is credited for which specific result, and which applications are recent. That is what /attribution-audit-network is for. The misattribution flagging uses the same data the field-map view does; we treat it below as a bonus view, not the headline.
Why AI?
Generic citation graphs treat the bibliography as the unit of analysis. They render edges between papers from shared citations or co-citation. That is the easy data: it lives in the bibliography of every indexed paper and any vendor can pull it. The field-map view sits one layer up.
Three things have to happen for the field map to be navigable. We need to read each paper’s methods section and extract a structured statement like “this paper uses CS not-yet-treated as its main estimator.” We need to normalize the method name against a synonym list (a controlled vocabulary that maps every variant spelling back to one canonical name) that knows “Callaway-Sant’Anna,” “CS DiD,” “doubly-robust DiD,” and “event-study CS” all refer to the same family. And we need to cluster papers, methods, and authors into a network with typed edges (links labeled by what kind of relationship they capture) for who developed what, who used it, who extended it, and who got the credit wrong.
Each of those steps is LLM-tractable with an operational definition and a verification gate. Methods-section reading scales because the per-paper cost is minutes of API time, not hours of a researcher. Name normalization runs against a versioned taxonomy with a manual-review queue for unmapped entries. Edge construction is rule-based on top of the extracted method-usage records. None of this work is in edge data alone.
Getting our bearings
A citation network in the conventional sense has papers as nodes and “X cites Y” as edges. The field-map network has more structure. There are three node kinds: papers, methods, and authors. The method nodes operationalize a taxonomy of causal-inference families: did-twfe, did-cs, did-sa, did-dcdh, sc-classic, sc-sdid, rd-sharp, rd-fuzzy, iv-2sls, iv-shift-share, causal-forests, and so on. Sibling families are explicit. Within DiD, did-cs (Callaway-Sant’Anna), did-sa (Sun-Abraham), and did-dcdh (de Chaisemartin-D’Haultfœuille) are distinct, and the catalog knows the distinction.
The edges are typed (each edge carries a label saying what kind of relationship it captures). develops means this paper is the named origin for a specific result. uses means this paper applies the method. mis-cites means this paper uses the method but credits a wrong-origin paper. claims_to_extend_misattributes means this paper claims to extend a method and cites the wrong origin for what it is extending. The first two edge types power the field-map view. The last two power the misattribution sub-layer.
“Canonical origin” deserves care. We mean the paper that first established the specific result a citer is using, not the paper that introduced the broader framework around it. Both can be seminal. The network shows both, with a develops edge for each, and lets the reader see the relationship.
What the tool does
The skill consumes three inputs: a curated catalog of known wrong-credit patterns (misattribution-catalog.yaml, mapping each method to its canonical-origin paper and the papers most often miscredited for it); a method-taxonomy file that lists the canonical names and synonyms extractors look for; and OpenAlex citation edges (the bibliography-level “X cites Y” links from the free OpenAlex bibliographic database) via the existing citation_network_expansion.py infrastructure. It emits a network with paper, method, and author nodes and the four edge types above. The misattribution catalog feeds the mis-cites edges; it does not gate the rest of the network.
The primary view is a method-family subgraph. The reader picks a family, the skill returns a layout, the reader sees the seminal papers as develops-edge anchors, the recent applications as uses edges sorted by year, and the authors as a roster projection. The misattribution sub-layer is a toggle.
A catalog entry follows a schema small enough to fit in one block. The honest-DiD entry looks like this:
# Sample misattribution-catalog.yaml entry
- method_family_id: did-honest
method_name: FLCI (fixed-length confidence interval)
canonical_origin:
doi: 10.1093/restud/rdad018
authors: Rambachan, A. & Roth, J.
year: 2023
journal: Review of Economic Studies
common_misattributions:
- cited_paper_doi: 10.48550/arXiv.2201.06710 # Roth 2022 working paper
reason: Earlier working paper introduces broader honest-DiD framework but does not contain the FLCI bound
synonyms: [FLCI, fixed-length CI, honest-DiD bound, Rambachan-Roth bound]
A paper gets flagged as miscrediting method X when four things are all true at once: the paper actually uses X as a main or robustness estimator (not just mentions it in a literature review), the paper’s bibliography includes a paper from the catalog’s “commonly mis-cited” list for X, the paper’s bibliography does NOT include the canonical-origin paper for X, and the same flag fires when we re-run the extractor with different settings (so it’s not a one-shot accident). Papers that cite BOTH the wrong paper AND the canonical origin are NOT flagged. They got attribution at least partially right, and the rule treats partial-correctness as a defense.
(Un)Tested
The skill is at v0.1, so the testing surface is narrower than what we want for production. We can describe what is in place, what has run, and what is specified but pending.
Sanity check. The shipped sixteen-entry catalog covers the FLCI-methodology miscite to RR 2023, the pretest-bias miscite to RR 2023, the Δ-restriction-framework miscite to Roth 2022, the not-yet-treated-comparison miscite to Sun-Abraham 2021, the doubly-robust ATT(g,t) miscite to Sun-Abraham 2021, the ARP/C-LF miscite to RR 2023, the causal-forests-vs-GRF pair, and nine other entries (surrogate-index attribution, Sun-Abraham proposition-number corrections, surname-form traps for Montiel Olea and Acemoglu). The seven entries that the v0.1 graph engine encodes (those with distinct wrong and correct DOIs) produced 136 nodes and 267 candidate edges in the full-catalog run, all at confidence=candidate-low. The sanity-check run on a 3-entry subset (cs-not-yet-treated, causal-forests, FLCI) returned 58 nodes and 57 edges and is preserved as the regression fixture. The full-catalog run confirms the pipeline runs end-to-end on real OpenAlex data across the catalog’s stratification; it does not confirm the flags are right.
Inference-rule verification. The four-condition flag rule fires on the sanity-check fixtures the way the specification says it should. A flag requires all four conditions in sequence: the paper actually uses the method as a main or robustness estimator, the bibliography contains a wrong-credit paper from the catalog, the bibliography does NOT contain the canonical-origin paper, and the same flag fires across two runs of the extractor at different settings. Papers that cite both the wrong paper and the canonical origin drop out, as designed.
Candidate-to-confirmed upgrade. Every candidate-low edge requires the papers-md-generator skill to run on the candidate paper and verify section-level evidence: that the paper actually USES the method in its methods or results section, not just mentions it in a literature review. The Goodman-Bacon false-positive case described below is the canonical demonstration of why section-evidence checking matters; the bibliography-presence test alone cannot distinguish “uses CS” from “discusses CS in lit review.”
Hand-coded validation. The spec calls for a 50-paper hand-coded validation set (a manually labeled gold standard against which the skill’s outputs are scored), stratified by method family (top 5 families, 10 papers each). The acceptance thresholds are asymmetric on purpose. Precision (the share of flagged papers that are real miscites) needs to clear 0.85 because the reputational stakes of a false positive are large. Recall (the share of true miscites the skill catches) is allowed to be lower at 0.60 because missing a flag is the kinder failure mode. A 10-paper hand-coded subsample (3 honest-DiD, 3 staggered-DiD, 4 causal-forests) returned precision = 0.20 with Wilson 95% CI [0.06, 0.51], well below the 0.85 target. Eight of the ten flagged candidates were survey papers, methodological reviews, or applied papers that cite a wrong-credit paper without applying the method as a main or robustness estimator. The 50-paper validation is still pending; the 10-paper result is enough to demonstrate that the bibliography-only rule cannot clear the precision threshold without section-evidence checking. Until section-evidence verification through /papers-md-generator lands, every flagged edge should be read as “candidate, pending verification,” not “confirmed misattribution.”
Cross-source validation pending. The Semantic Scholar API key returns HTTP 403 on the paper, recommendations, and datasets endpoints; the unauthenticated tier returns HTTP 429 on the same endpoints. That pattern is consistent with a deactivated or revoked key, not a rate-limit issue or a malformed request. v0.1 runs on OpenAlex alone. Once the key is reissued through the Semantic Scholar API key program, v0.2 will cross-validate citation edges across both sources, which gives a second independent witness for every flagged miscite.
Walking through a run
Let’s pick honest DiD as the family and walk the views in order.
(a) Invoke the skill. /attribution-audit-network family=honest-did. The skill pulls OpenAlex edges for papers that cite Roth 2022 or Rambachan and Roth 2023, runs the extractor over the candidate set, normalizes method names, and emits a network.
(b) Seminal papers. Three develops edges anchor the family, not two. Roth (2022, AER:Insights) introduces the pretest-bias diagnostic and the low-power result for pre-trends tests. Rambachan and Roth (2023, Review of Economic Studies) introduces the constructive sensitivity framework with Δ-restrictions (Δ^RM, Δ^SD) and the breakdown-M discussion. Armstrong and Kolesár (2018, Econometrica) introduces the FLCI (fixed-length confidence interval) methodology that RR 2023 adapts for Δ^SD. All three are legitimately seminal for the family, and the network shows all three. A reader who wants to cite “the FLCI” sees the Armstrong-Kolesár anchor and the RR 2023 adapter. A reader who wants to cite “pretest bias” sees the Roth 2022 anchor. A reader who wants the constructive sensitivity framework sees the RR 2023 anchor. The network surfaces this structure rather than collapsing the family to a single canonical citation.
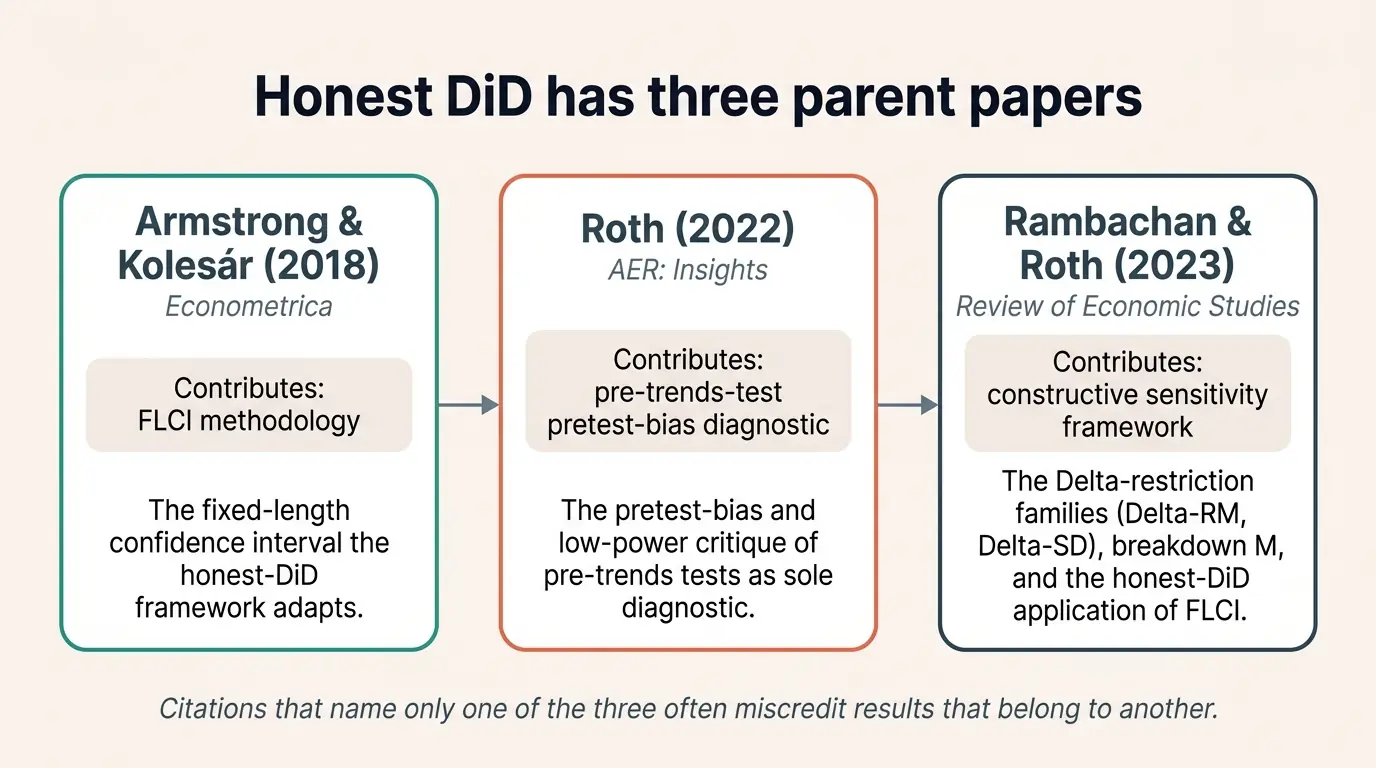
Honest DiD has three parent papers, each contributing a different result. Citing only one when the result lives in another is the misattribution pattern the catalog catches.
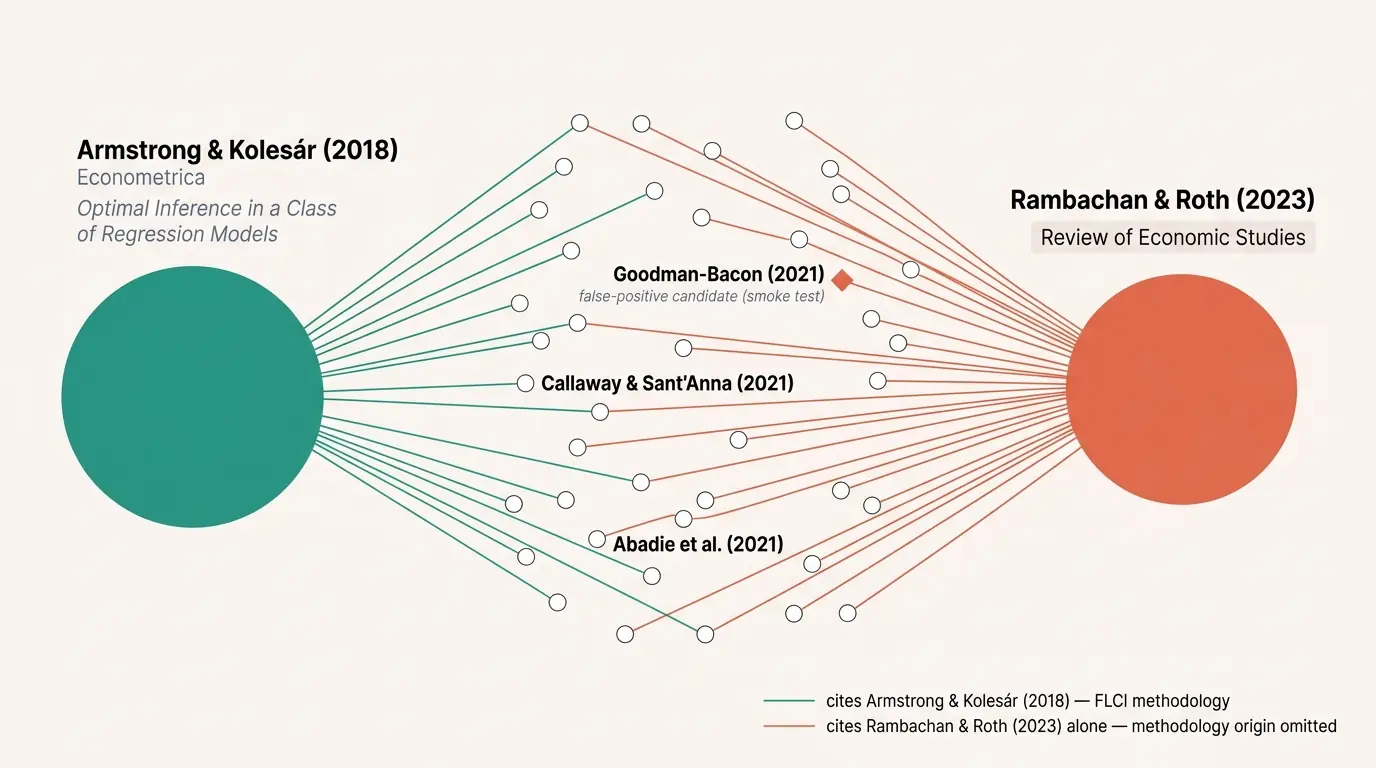
FLCI methodology miscites. Twenty-four citing papers in the preliminary catalog credit RR 2023 alone for the fixed-length confidence interval (FLCI), omitting Armstrong and Kolesár (2018, Econometrica) where the FLCI machinery itself was introduced. RR 2023 adapts FLCI for the Δ^SD honest-DiD setting; citing both is the right move. One node is flagged candidate-low and is the canonical v0.1 false-positive case; section-evidence checking in v0.2 will demote it.
(c) Who is in the field. The author projection collapses paper nodes into author nodes, weighted by their incident develops and uses edges. Roth and Rambachan show up as the heavy nodes. The roster also surfaces applied authors whose recent papers use honest DiD as a main or robustness estimator. The output is a list, not a guess. If we are looking for a referee suggestion, an external reader for a draft, or a sense of which subfields have adopted the method first, we are reading a roster rather than skimming author affiliations on Google Scholar pages.
(d) Recent work. The uses edges are date-sorted. The reader can see what has been published in the last year that applies honest DiD, with each paper’s role (main vs. robustness) attached. For methods-section drafting, this is the most useful single view: a recent applied paper that uses the method we are about to use, indexed by year and by role. The point is not that the recent paper is more authoritative than the seminal paper. The point is that the recent paper shows the implementation choices reviewers expect now, which the 2023 RES paper cannot show because it predates the choices.
(e) Bonus: misattribution flags. With the misattribution toggle on, the same network surfaces about 24 papers in the sanity-check catalog that credit the FLCI methodology to Rambachan and Roth (2023) alone, omitting Armstrong and Kolesár (2018, Econometrica) where the FLCI machinery itself was introduced. The flag reads: paper P claims to use FLCI in its methods section, AND P’s bibliography contains RR 2023, AND P’s bibliography does NOT contain Armstrong-Kolesár 2018. Citing both is correct; citing only RR 2023 omits the methodology origin. A single flagged edge serializes like this:
{
"edge_type": "mis-cites",
"method_family": "did-honest",
"citing_paper": {
"doi": "10.xxxx/example",
"title": "...",
"year": 2024
},
"wrong_credit": {
"doi": "10.48550/arXiv.2201.06710",
"label": "Rambachan & Roth 2023 (Review of Economic Studies)"
},
"canonical_origin_missing": {
"doi": "10.1093/restud/rdad018",
"label": "Armstrong & Kolesár 2018 (Econometrica) — FLCI methodology"
},
"confidence": "candidate-low",
"self_consistency_gate": "passed",
"section_evidence_check": "pending (run /papers-md-generator)"
}
That is a candidate misattribution, not a confirmed one. To upgrade, we pass the candidate through the sister skill /papers-md-generator, which reads the methods section and verifies the method-usage claim and the bibliography state.
The Goodman-Bacon case sits in the v0.1 candidate list as a known false positive. Goodman-Bacon 2021 is the DiD-decomposition paper, not an application of CS DiD, and the extractor flagged it because the literature-review section mentions Callaway and Sant’Anna. The v0.1 extractor cannot yet distinguish “uses CS” from “mentions CS in lit review”; the candidate-low label holds the flag in a probationary state, and v0.2 integration with the sister skill will check section evidence (looking at where in the paper the method is mentioned) rather than bibliography presence alone. The same JSON for the Goodman-Bacon edge looks like this:
{
"edge_type": "mis-cites",
"method_family": "did-cs",
"citing_paper": {
"doi": "10.1016/j.jeconom.2021.03.014",
"title": "Difference-in-differences with variation in treatment timing",
"year": 2021,
"authors": "Goodman-Bacon, A."
},
"wrong_credit": {
"doi": "10.1016/j.jeconom.2020.12.001",
"label": "Callaway & Sant'Anna 2021"
},
"canonical_origin_missing": {
"doi": null,
"label": "n/a (Goodman-Bacon does not USE CS DiD; it discusses it in lit review)"
},
"confidence": "candidate-low",
"self_consistency_gate": "passed",
"section_evidence_check": "pending (v0.2 will demote to 'no flag (literature-review mention)')"
}
Adapting for other method families
The catalog and taxonomy ship with sixteen entries seeded from three families we work in regularly. A reader with a different method family in their working area, say shift-share IV, bunching estimators, regression-kink designs, marginal-effect heterogeneity, or weak-instrument robust inference, can extend the skill in three steps of increasing effort.
Add catalog entries for the methods we work in. This is the lightest lift. A catalog entry is a YAML block that names the wrong-credit paper, the correct-credit paper, the method being misattributed, and the source-of-claim citations that justify the correction. The schema is the same one shown earlier for honest DiD. We copy it, fill in wrong_credit, correct_credit, method, and sources_of_claim, drop it into shared/misattribution-catalog.yaml, and the orchestrator picks it up the next time it runs. Surface forms (the textual aliases an extractor might see for the wrong-credit paper) belong in the same block so the future LLM extractor matches against them. The orchestrator skips entries that don’t have distinct DOIs on both sides, so a catalog entry can ship in a near-stub state and start working as soon as both DOIs resolve on OpenAlex.
Add a method-family entry to the taxonomy. The taxonomy file keys each family by its canonical-origin DOI plus a list of synonyms (the spelling variants extractors should map back to the same family). To add shift-share IV, we’d add a family_id like iv-shift-share, set the canonical origin to Bartik (1991, Who Benefits from State and Local Economic Development Policies?, Upjohn Institute, DOI 10.17848/9780585223940) with Goldsmith-Pinkham, Sorkin, and Swift (2020, American Economic Review, DOI 10.1257/aer.20181047) as the identification-conditions reference, list synonyms (shift-share IV, Bartik instrument, Bartik IV, Goldsmith-Pinkham-Sorkin-Swift Bartik), and link related families. The network expander queries OpenAlex on the family DOI to find seminal, current, and recent-application papers; once the entry lands, the field-map view comes back populated.
shared/ at the repo root. The catalog loader (lib/catalog_loader.py) takes the file path from TETS_CATALOG_PATH and TETS_TAXONOMY_PATH environment variables, falling back to the canonical post-install location. To run against our own forked catalog without touching the shipped one, we set those env vars at invocation time. The skill's actionable_entries() function in the same module enforces the "must have distinct wrong and correct DOIs" rule, so half-finished entries get skipped without breaking the run.
Extend the 4-condition flag rule. Some misattribution patterns the 4-condition rule cannot catch as-shipped. The most common is working-paper-to-journal drift: a method gets credited to an NBER working paper or an arXiv preprint when the canonical-origin citation should be the journal version, or vice versa. The current rule treats those as separate DOIs and would (incorrectly) flag a paper that cites only the journal version as a misattributor of the working paper. The catalog handles this for the surrogate-index case by carrying both doi (NBER WP) and journal_doi (Review of Economic Studies 2025) on the correct_credit block, and the resolver in lib/catalog_loader.py treats either DOI as a valid “got the canonical origin right” signal. To extend that pattern to a new method family, we add journal_doi (or working_paper_doi) on the correct-credit block; the correct_origin_resolution_dois property collects all valid DOIs, and the detector in lib/misattribution_detector.py accepts any of them.
lib/misattribution_detector.py:detect_for_pair() normalizes DOIs and tests bibliography membership against the set of correct-origin DOIs returned by catalog_entry.correct_origin_resolution_dois. The set is built from both doi and journal_doi on the catalog entry's correct_credit block, so adding either field is enough to teach the rule about a new working-paper-to-journal pair. For methods where the canonical credit is itself contested between two papers (Theil 1953 vs Basmann 1957 for 2SLS, for example), the taxonomy carries an additional_candidates list and the misattribution-trap engine is expected to surface all candidate originators per the original specification.
Next steps
What got run after we wrote v0.1. The catalog now carries sixteen entries: the honest-DiD pillar (FLCI methodology, pretest-bias diagnostic, Δ-restriction sensitivity framework, ARP/C-LF inference), the staggered-DiD pillar (Callaway-Sant’Anna vs Sun-Abraham on the doubly-robust estimator and the not-yet-treated comparison), causal forests vs Generalized Random Forests, the surrogate index, three Sun-Abraham proposition-number corrections, and surname/author-order traps for weak-instrument inference and pro-worker AI. Re-running the orchestrator against the full catalog produced 136 nodes and 267 candidate mis-cites edges across the seven v0.1-actionable entries (the other nine are either single-paper-section traps or surname-form errors that the v0.1 graph engine does not encode).
A 10-paper hand-coded subsample stratified across the three method-family groups (3 honest-DiD, 3 staggered-DiD, 4 causal-forests) returned precision = 0.20 with a Wilson 95% interval of [0.06, 0.51]. The spec sets the acceptance threshold at precision ≥ 0.85 for the bibliography-only flag, and the 10-paper subsample lands far below it. The failure mode is consistent across the strata: most candidates that the bibliography rule flags are survey papers, methodological reviews, and applied papers that cite a wrong-credit paper without applying the method as a main or robustness estimator. Precision under the bibliography-only rule is structurally bounded by the proportion of citing-paper bibliographies that contain the wrong-credit DOI because the citer actually USES the method (the target population), rather than because the citer surveys the literature, contrasts the method against another, or cites it as related work. The 50-paper validation specified in the original protocol is still pending; the 10-paper subsample is enough to demonstrate that section-evidence checking through /papers-md-generator is not a v0.2 nice-to-have but a v0.2 prerequisite. Recall on the detector-flagged set is not computable from this subsample alone (recall against the population of true miscites requires a gold-labeled corpus the detector has not seen).
The Semantic Scholar API key returns HTTP 403 on the paper, recommendations, and datasets endpoints when called with the issued key, and the unauthenticated tier returns HTTP 429 (rate limit) on the same endpoints. That pattern points to a deactivated or revoked key rather than a malformed request (which would return 400 or 404), a rate limit (which would return 429 with the same key), or a tier mismatch. v0.1 runs on OpenAlex alone; cross-source validation against Semantic Scholar is parked until the key is reissued through the Semantic Scholar API key program.
Worth taking with us
The cost of getting our bearings in a new method family drops from a half-day of citation-walking to one skill invocation. The catalog is the schema, not the database; running the skill against our own catalog gets us the field map for our own literature. The misattribution layer uses that same data: if the catalog names the canonical-origin and wrong-credit DOIs, the flags appear without extra work.
Have input? Get in touch.
References
[1] Callaway, B., & Sant’Anna, P. H. C. (2021). Difference-in-differences with multiple time periods. Journal of Econometrics, 225(2), 200-230. https://doi.org/10.1016/j.jeconom.2020.12.001
[2] Rambachan, A., & Roth, J. (2023). A more credible approach to parallel trends. Review of Economic Studies, 90(5), 2555-2591. https://doi.org/10.1093/restud/rdad018
[3] Sun, L., & Abraham, S. (2021). Estimating dynamic treatment effects in event studies with heterogeneous treatment effects. Journal of Econometrics, 225(2), 175-199. https://doi.org/10.1016/j.jeconom.2020.09.006
[4] Goodman-Bacon, A. (2021). Difference-in-differences with variation in treatment timing. Journal of Econometrics, 225(2), 254-277. https://doi.org/10.1016/j.jeconom.2021.03.014
Cite this article
Cholette, V. (2026, May 25). A field map for causal-inference methods. Too Early To Say. https://tooearlytosay.com/research/methodology/attribution-audit-network/