If we have not used Claude Code before, the three tool articles in this series (papers-md-generator, replication-package-analytics, attribution-audit-network) read past a setup step we haven’t taken. This piece fills the gap. The audience is applied economists who write Stata or R, who have used Claude or ChatGPT through a web interface, but who have not run Claude as a CLI tool in their terminal. The goal: get from “I want to try this” to a successful first invocation in about 90 seconds of reading plus whatever the installer takes.
Claude Code is not the web chat
Claude.ai is a web interface; we type, Claude responds, the conversation lives in the browser. Claude Code is something else. It is a command-line program from Anthropic that wraps the same Claude model with three extra capabilities: it can read files in our working directory, write files back, and execute shell commands when we ask it to. That means a Claude Code session can open a paper PDF on our laptop, parse it, write a structured summary to a new file, and commit the result to git, all without us copy-pasting through a browser.
Claude Code runs in a terminal. The TETS skills described in the tool series load into Claude Code on startup and become invocable from the session prompt as /<skill-name>. None of them runs in the web chat.
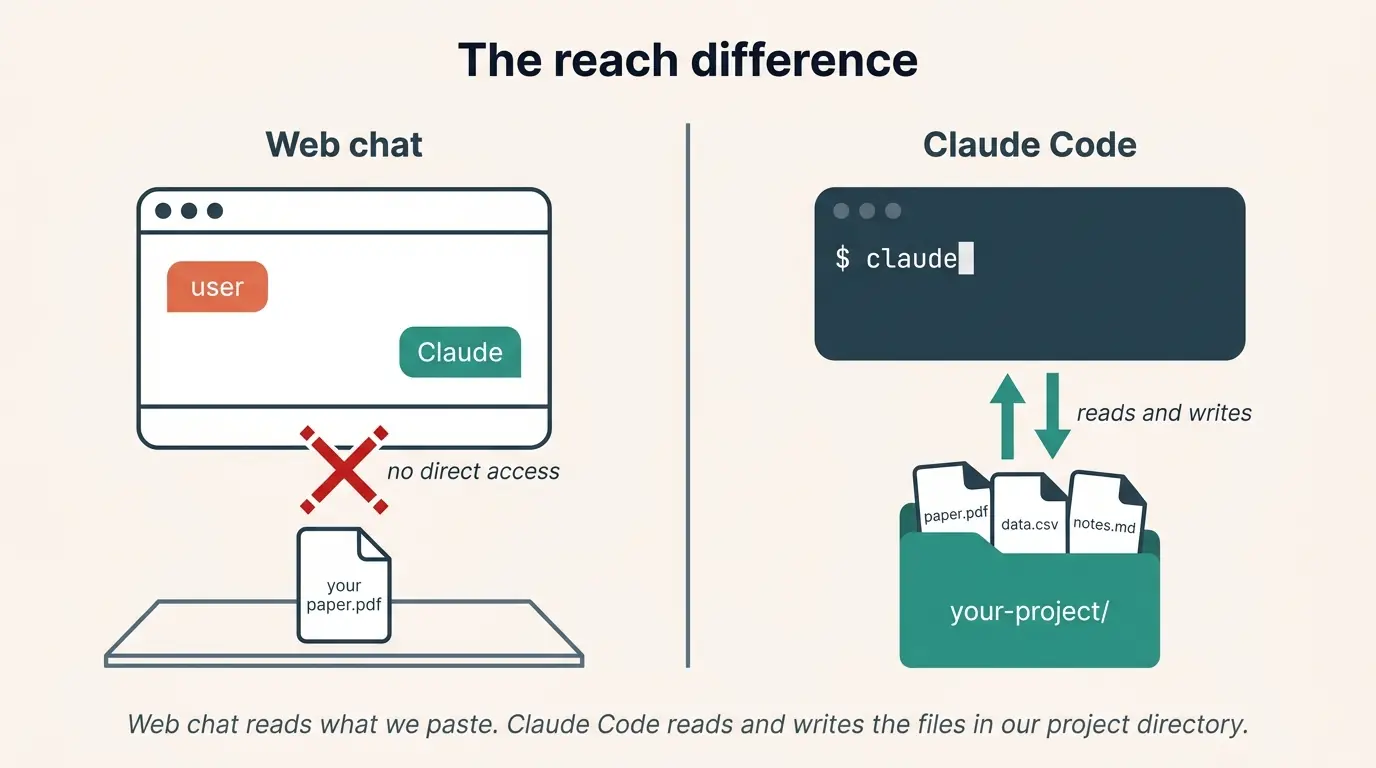
Web chat reads what we paste. Claude Code reads and writes the files in our project directory.
What a skill is, in one paragraph
A skill is a folder. The folder has a SKILL.md file that tells Claude what the skill does and how to invoke it. The folder usually has supporting scripts, schema files, and reference docs alongside the SKILL.md. When Claude Code starts a session, it looks for skill folders under ~/.claude/skills/ (or under .claude/skills/ in the current project directory) and loads each one. Skills appear in the session as /<skill-name> slash-commands, much like /help or /clear in any chat interface, except these are project-specific and load from disk.
For the TETS skills, the folder structure is roughly:
.claude/skills/papers-md-generator/
├── SKILL.md
├── src/
│ ├── extractor.py
│ ├── grobid_client.py
│ ├── normalizer.py
│ └── ...
├── tests/
└── fixtures/
The SKILL.md is the contract. The Python files are the helpers Claude calls when we invoke the skill.
Installing Claude Code
Anthropic maintains the canonical install instructions; the exact command shifts as versions release. As of this writing, the install path on macOS or Linux is roughly:
npm install -g @anthropic-ai/claude-code
claude --version
The first command installs Claude Code globally via npm (Node Package Manager). If npm is not on the machine, install Node.js first from nodejs.org. The second command verifies the install worked. On first run, Claude Code prompts for either a subscription login (browser-based) or an ANTHROPIC_API_KEY environment variable. Either path works; the subscription is usually cheaper for sustained interactive use, the API key is cleaner for scripts and CI.
The official Anthropic Claude Code docs are the source of truth for the install command and authentication flow. Follow those if the instructions here have drifted.
Getting the TETS skills
The skills are public at github.com/dphdame/tets-claude-skills under an MIT license. v0.1.0 is the current tag.
git clone https://github.com/dphdame/tets-claude-skills.git
cd tets-claude-skills
mkdir -p ~/.claude/skills
cp -r papers-md-generator replication-package-analytics attribution-audit-network shared ~/.claude/skills/
pip install -r ~/.claude/skills/papers-md-generator/requirements.txt \
-r ~/.claude/skills/replication-package-analytics/requirements.txt \
-r ~/.claude/skills/attribution-audit-network/requirements.txt
The shared/ directory holds the misattribution catalog and method taxonomy YAMLs that two of the skills read; it must sit next to the skill folders. Restart Claude Code after copying, and /papers-md-generator, /replication-package-analytics, and /attribution-audit-network appear in the session command list.
The first practical question once we have the skills installed is which one to try first. The lowest-barrier choice is replication-package-analytics on Path A: it runs against publicly cached openICPSR metadata via the Wayback Machine, needs no local Docker, no GROBID, and no OpenAlex credentials beyond the public rate limit. papers-md-generator needs GROBID running locally (which means Docker), and attribution-audit-network needs the misattribution-catalog YAML alongside the skill files. The other two are richer demos, but Path A on replication-package-analytics is the friction-cheapest entry point.
What the first invocation looks like
Open a terminal. Navigate to a project directory where we want the skill to write its output:
cd ~/projects/replication-survey
Start Claude Code:
claude
Wait for the session prompt. Type the skill invocation:
/replication-package-analytics mode=smoke
The skill runs inside the session. It reads a seed list of openICPSR project IDs (the smoke set ships with the skill), queries Wayback for each, runs the static-analyzer pipeline over whatever metadata the Wayback snapshot contains, and writes one JSON record per package to the project directory. A run typically takes a few minutes. The session output narrates the steps as the skill executes.
When the run finishes, the JSON records sit in the project’s output directory. We can open them in our editor of choice, load them into a notebook, or query them with jq. The panel-of-metrics CSV is one further step away (documented in the tool article).
A note on GROBID and Docker for papers-md-generator
papers-md-generator extracts methods-section structure from PDFs. PDF parsing is delegated to GROBID, which runs as a local service. The conventional way to run GROBID is Docker:
docker pull lfoppiano/grobid:0.8.0
docker run -t --rm -p 8070:8070 lfoppiano/grobid:0.8.0
If we have not used Docker before, this is a real setup step. Docker Desktop is a free download for macOS, Linux, and Windows. The first run pulls the GROBID image, which is several hundred megabytes. Once GROBID is running, papers-md-generator queries it on localhost:8070 and the rest of the skill pipeline runs.
For applied economists who write only Stata and have never installed a containerization runtime, this is the largest friction point in the series. If Docker is a non-starter, replication-package-analytics on Path A is the lowest-friction entry; attribution-audit-network needs no Docker either, only the catalog YAMLs alongside the skill.
What to read next
The three tool articles assume the setup above is in hand:
- A reference library for empirical methods walks the papers-md-generator skill end to end, including the misattribution-trap engine and the worked Callaway-Sant’Anna example.
- A common shape for econ replication packages walks the replication-package-analytics skill, including Path A vs Path B and the twelve compliance metrics.
- A field map for causal-inference methods walks the attribution-audit-network skill, including the misattribution catalog and the worked FLCI / Armstrong-Kolesár / Rambachan-Roth example.
Each of those articles opens with the felt problem the skill addresses, then walks the mechanism, the validation status, and one worked example. The setup here is the prerequisite for actually running any of them.
Have input? Get in touch.
Cite this article
Cholette, V. (2026, May 26). Running Claude Code skills, for applied economists. Too Early To Say. https://tooearlytosay.com/research/methodology/claude-code-skills-setup/