Before We Begin
This article builds on the Intermediate tier, which covers:
- The Cold Start Problem - Setting up CLAUDE.md
- End-of-Session Hygiene - Preserving context across sessions
- Context Window Budgeting - The whiteboard metaphor
- The Verification Tax - Building trust through verification
The Intermediate tier covered context discipline. This tier builds infrastructure.
A single conversation has limits.
The whiteboard fills up. Focus drifts. We start exploring a tangent and suddenly the main thread is buried under details we did not need to retain. By the time we return to the original question, we have used up whiteboard space on exploration that led nowhere.
This is where helpers come in. The idea: hand off work to someone who explores, executes, and reports back. We get the result without the journey cluttering our main conversation.
What Is a Helper (Agent)?
Think about how we work with research assistants. We give them a focused task - "gather papers on staggered DiD (difference-in-differences) estimators" - and they go off, do the work, and come back with materials. We do not need to watch every step. We trust them to explore, hit dead ends, and figure things out. What we care about is the materials gathered for our review.
Claude Code can create these kinds of helpers. In the documentation, they are called "agents," but the concept is the same as delegating to an RA. Each helper:
Gets a fresh whiteboard: The helper has its own workspace, completely separate from our main conversation. Its exploration does not use up space in our conversation.
Focuses on one task: We give the helper a specific job. It works on that and nothing else.
Reports back with a summary: When the helper finishes, we get a summary of what it found or did. Not the full transcript of its thinking, just the results.
Keeps dead ends to itself: Rejected approaches, wrong turns, and exploratory tangents stay in the helper's workspace. Our main conversation stays clean.
The mental model: we are the principal investigator delegating to a research assistant. We give clear instructions, they do the work, they report back. We do not need to watch every step.
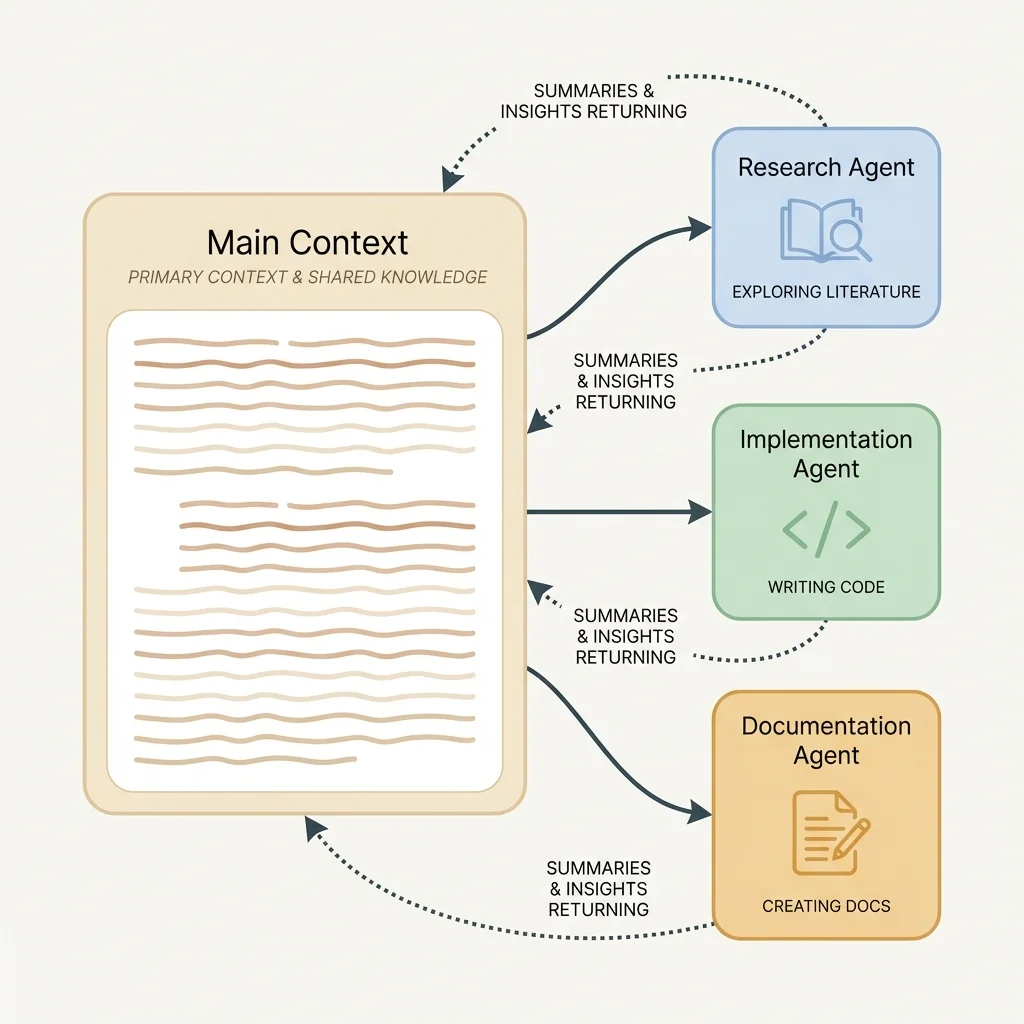
How to Create a Helper
When we want to delegate work, we describe the task and Claude Code creates a helper to handle it. The helper gets its own fresh workspace, works until the task is complete, and returns a summary.
Two Ways to Create Helpers
We can create helpers in two ways: natural language or explicit delegation. Both work. The choice depends on how specific we want to be.
Natural language (simplest): Just describe what we want researched or done, and Claude will create the helper automatically.
"Research alternative estimators for difference-in-differences
with staggered treatment timing. Compare Callaway and Sant'Anna,
Sun and Abraham, and Borusyak et al."Claude recognizes this as a research task that benefits from delegation and creates a helper without us specifying the mechanics. The key is being clear about what we want: scope, deliverables, and success criteria. If we are vague, Claude might attempt the task in the current conversation instead of delegating it.
Explicit delegation (more control): We can explicitly ask Claude to delegate, which gives us more control over the process.
"Create a helper to research this. I want it to run in the
background while we continue discussing the identification strategy."Or we can be even more specific:
"Spawn a research agent to explore synthetic control methods.
Have it focus on inference approaches and return a comparison
of permutation tests vs. conformal inference."The explicit approach is useful when we want to:
- Run the helper in the background while continuing other work
- Specify which type of helper to use (research, implementation, documentation)
- Create multiple helpers simultaneously for parallel research
What the Helper Needs from Us
Task description: Clear instructions for what the helper should accomplish. This is the most important part. Vague instructions lead to useless results.
Helper type: Different types of helpers have different strengths. Research helpers explore questions. Implementation helpers write code. Documentation helpers generate and review docs.
Summary return: The helper returns a summary, not the full conversation. We see what it concluded or produced, not every step of how it got there.
Completion handling: Helpers run until they finish the task or hit limits. We can wait for completion or continue working while helpers run in the background.
A typical delegation might look like:
"Find papers published 2020-2024 that implement difference-in-differences with staggered treatment timing using Callaway and Sant'Anna, Sun and Abraham, or Borusyak et al. For each paper, pull: the estimator used, the data structure, and any stated limitations."
The helper searches, gathers papers, and extracts the specific information we requested. All of that retrieval stays in its workspace. We get the materials to interpret ourselves.
When to Delegate vs. Keep in Our Conversation
This is the core decision. Not every task benefits from delegation. Some work should stay local.
Delegate when exploration might hit dead ends.
If we are not sure which identification strategy will hold up, create a helper to explore. It can read three papers on instrumental variable approaches, find that two rely on assumptions that do not fit our context, and report on the one that does. We do not use up our whiteboard space on the failures.
Delegate when we need materials gathered, not interpreted.
If we need papers collected, citations verified, or data pulled from multiple sources, delegation makes sense. Retrieval tasks fit this pattern. We want the materials organized for our review, not every search query the helper tried.
Delegate when running multiple tasks at the same time would be faster.
Independent tasks can run simultaneously. Three helpers researching three robustness check approaches finish faster than researching them one after another.
Keep local when we need to iterate on results.
If we are going to take the first draft of a data cleaning script and refine it through multiple rounds of feedback, keep it in our conversation. The iteration history matters for the next refinement.
Keep local when the reasoning process informs next steps.
Sometimes how we got an answer matters as much as the answer. If understanding the derivation will shape our model specification, keep the exploration visible.
The heuristic: delegate for breadth, keep local for depth.
Breadth means exploring options, comparing identification strategies, gathering information from multiple papers. Helpers excel here because each exploration is independent.
Depth means iterating, refining, building understanding through back-and-forth. This benefits from continuous conversation where each exchange builds on the last.
A deeper principle: we can outsource what we can name and verify.
This is the rule that underlies all delegation decisions. If we can describe a task precisely enough to hand it off, and if we can check whether the result is correct, delegation works. If either piece is missing—if we cannot articulate what we want, or if we would not recognize a wrong answer—delegation produces waste.
Consider the difference: "Find papers on DiD" is hard to verify. Did the helper miss important work? Did it include irrelevant papers? We would need to redo the search ourselves to know.
But "Find five empirical papers published 2020-2024 using staggered DiD with heterogeneity-robust estimators in labor economics, noting which estimator each uses" is verifiable. We can check whether the papers exist, whether they use the stated methods, whether they are from the right period. If the helper returns four papers, we know it fell short. If it returns papers from 2018, we know something went wrong.
The ability to name the task precisely and verify the result independently—these are the prerequisites for delegation. Without them, we are not outsourcing work; we are generating material we cannot trust.
Types of Helpers Available
Different helper types bring different capabilities:
Research helpers explore questions and gather relevant findings. They are good at locating methodological alternatives, surveying how other papers handle identification, and organizing what they find. The return is typically a structured collection with key points and tradeoffs for our review.
Implementation helpers write code, create files, and run tests. They execute the work rather than just researching it. The return includes what they built and any issues they encountered.
Documentation helpers generate docs, review for completeness, and check consistency. They are useful for creating codebooks that document variables systematically.
Custom helpers receive task-specific instructions for specialized work. We can define exactly what we need: "Review all merge operations in the data cleaning pipeline and list potential sources of observation loss."
Matching helper type to task:
- "How do other papers handle this identification problem?" - Research helper
- "Write a cleaning script for ACS microdata" - Implementation helper
- "Generate a codebook for our constructed variables" - Documentation helper
- "Find all places we make sample restrictions and document the justification" - Custom helper with specific instructions
Designing Tasks That Are Easy to Hand Off
The quality of helper output depends on the quality of task design. Vague tasks produce vague results.
Clear scope: the helper knows when it is done.
Bad: "Look into difference-in-differences."
Better: "Research recent critiques of two-way fixed effects DiD with staggered adoption. Summarize the Goodman-Bacon decomposition and explain when negative weights become a problem. List which alternative estimators are commonly used for settings with staggered adoption and note their tradeoffs."
The better version has a clear deliverable. The helper knows what success looks like.
Sufficient context: the helper has what it needs.
Bad: "Find papers on SNAP."
Better: "Search for recent empirical papers (2018-2024) examining SNAP's effect on food security outcomes. Focus on papers using quasi-experimental designs. For each paper found, note: identification strategy, main data source, and key finding on food security measures."
The better version gives scope, timeframe, and the specific information we need extracted.
Success criteria: what does a good result look like?
Bad: "Research robustness checks."
Better: "Research robustness check approaches for regression discontinuity designs. Return a comparison of at least three approaches with: (1) what assumption each tests, (2) how to implement it, (3) how to interpret failure."
The better version specifies the structure of a useful response.
Failure handling: what if the helper cannot complete the task?
Tasks should allow for partial success. "If the paper does not report the statistic we need, note that and move to the next candidate" is better than assuming everything will work perfectly.
A well-designed task example:
"We need to understand how other researchers have handled selection into treatment for job training programs. Research three to five recent papers on job training evaluation. For each, document: (1) how they addressed selection bias, (2) what data they used for the identification strategy, (3) any limitations they acknowledge. Note which approaches might apply to settings with administrative data on program applicants but not non-applicants."
This task has scope, context, structure, and clear success criteria.
Running Multiple Helpers at the Same Time
One of the most powerful patterns: having several helpers work simultaneously on independent tasks.
The setup: We need to explore three different approaches to handling an identification problem. Instead of researching them one after another in our main conversation, we create three helpers:
Helper 1: "Research how papers using the synthetic control method handle inference. Focus on permutation tests and recent developments in confidence intervals."
Helper 2: "Research the matrix completion approach to synthetic control. Explain when it outperforms the original Abadie method and implementation requirements."
Helper 3: "Research the augmented synthetic control method. Compare to standard synthetic control and explain the bias correction."
All three work at the same time. When they complete, we have three focused summaries to compare.
The benefit: Running tasks simultaneously is faster than doing them one after another. Each helper also brings full attention to its task without work from the other explorations diluting focus.
Waiting for completion: We can wait for all helpers to finish before proceeding, or continue other work while helpers run in the background. For literature review tasks, waiting is usually fine. For long-running data processing scripts, background work lets us stay productive.
Combining results: When helpers return, we synthesize their findings in our main conversation. This is where our judgment matters: which approach best fits our research design? The helpers gathered the information; we make the decision.
Practical limit: Creating too many helpers has diminishing returns. Three to five working at once is usually productive. Beyond that, we spend more time synthesizing results than we save by running tasks simultaneously.
Patterns to Avoid
Some patterns waste the power of helpers or create friction:
Delegating trivial tasks.
If the task takes less time than formulating the delegation, do not create a helper. "What is the Stata syntax for fixed effects regression?" does not need a helper. Just ask.
The overhead of delegation should be smaller than the work being delegated.
Delegating when we need to iterate.
Helpers return summaries, not interactive sessions. If we know we will want to say "that code is close, but adjust the merge logic," keep it local. The iteration history matters, and we lose it with helpers.
Vague task descriptions.
"Research instrumental variables" tells the helper nothing about what we actually need. The result will be generic, probably not addressing our specific identification problem.
Every minute spent clarifying the task upfront saves five minutes of useless results.
Too many helpers at once.
Creating ten helpers to explore ten different robustness checks feels efficient but creates synthesis problems. We end up with so much output that making sense of it takes longer than focused research done one topic at a time would have.
Three to five is usually the sweet spot.
Forgetting to act on helper results.
A helper returns findings on alternative estimators. We read them and then... get distracted by a data issue. The research sits unused. The methodological recommendation never gets implemented.
Helper results are only valuable if we do something with them. Close the loop.
Using helpers to avoid thinking.
Helpers are for delegating work, not delegating judgment. "Should we use matching or IV?" is a question we answer, informed by helper research. The helper gathers information; we make decisions.
Practical Examples
Let us walk through some real scenarios:
Scenario 1: Gathering materials on identification strategies
We are studying the effect of a state policy and need to understand what identification approaches exist. Instead of searching in our main conversation:
Create a helper: "Find textbook chapters and survey articles covering identification strategies for state-level policy effects with staggered adoption. Pull the data requirements and key assumptions for event study, synthetic control, and heterogeneity-robust DiD. List 3-5 recent applications in labor economics for each approach."
The helper gathers the materials and organizes them. We review and decide which approach fits our setting.
Scenario 2: Pulling data documentation
We need to work with Census microdata and want to find the relevant documentation:
Create a helper: "Read the IPUMS documentation for the American Community Survey. Pull: (1) the exact construction of employment status from underlying variables, (2) the universe restrictions for labor force questions, (3) any documented changes in variable definitions between 2010 and 2020. Organize by variable name."
The helper reads documentation, extracts the specific information, and organizes it. We get the materials without using up main conversation space on dense technical material.
Scenario 3: Gathering papers with multiple helpers
We are writing a literature review section and need to collect papers across three strands of research:
Helper 1: "Find five papers on employment effects of minimum wage increases published 2018-2024. For each, pull: citation, research design, data source, sample size."
Helper 2: "Find five papers on minimum wage effects on prices and pass-through, same period. Pull same fields."
Helper 3: "Find five papers on minimum wage effects on firm entry and exit, same period. Pull same fields."
All three return organized paper lists with the specific fields we requested. We read the papers and write the synthesis ourselves.
Scenario 4: Implementation delegation
We need a data cleaning script but do not want to context-switch from our identification strategy work:
Create a helper: "Create a Python script in src/cleaning/acs_clean.py that loads ACS microdata, restricts to prime-age workers (25-54), constructs a labor force participation indicator, and handles the survey weights. Include docstrings explaining each step. Create test cases using a small sample to verify the logic."
The helper writes, tests, and reports. We review the result when we are ready.
Building the Habit
Helpers become more useful as we develop intuition for when to delegate:
Start noticing the decision point. When we are about to dive into a literature tangent, pause. Is this exploration we need to see, or just findings we need?
Default to delegating for literature review. Most "how do other papers handle X" questions are good helper candidates.
Keep iteration local. When we are refining code, building a model specification, or having a back-and-forth about variable construction, that is local work.
Review helper outputs promptly. Results get stale. Act on them while context is fresh.
Refine task descriptions over time. Notice when helper outputs miss the mark. Usually the task description was too vague. Next time, be more specific about the identification context or data constraints.
The goal is natural delegation: recognizing the tasks that benefit from separation and creating helpers without friction.
This Is Iterative Development
Effective use of helpers is a skill that develops over time. We do not master it immediately, and that is fine.
The first few times we delegate, the results may disappoint. Task descriptions that seemed clear to us were ambiguous to the helper. Scope was too broad or too narrow. Success criteria were missing. This is normal and expected.
Each delegation teaches us something. We notice patterns: which tasks delegate well, which phrases produce useful outputs, which success criteria actually verify completion. We refine our mental model of what helpers can do.
Think of it as managing a new research assistant. The first assignments require more guidance and produce more misses. Over time, we learn how to communicate effectively, and the assistant learns what we need (or in this case, we learn what the system needs to understand our requests).
Do not expect perfection from the start. Expect iteration. Expect refinement. That is how every useful research practice develops.
Practical Recommendations
- Start with literature tasks. Helpers excel at "compare three methodological approaches and summarize" work. Build intuition there before trying implementation delegation.
- Be specific in task descriptions. Every constraint and success criterion we add improves output quality.
- Use multiple helpers for independent comparisons. Three helpers researching three identification strategies beats sequential research.
- Do not delegate for iteration. If we will want to say "close, but adjust the sample restriction," keep it local.
- Act on results. Helper output is only valuable if we do something with it. Close the loop.
- Watch for the overhead trap. If formulating the task takes longer than doing the work, just do the work.
Helpers extend what a single session can accomplish. Use them to maintain focus while exploring breadth.
This is Article 1 of 5 in the Claude Code Guide - Advanced Tier. The series continues with skills, hooks, integrations, and putting it all together into personal AI infrastructure.
Suggested Citation
Cholette, V. (2026, February 25). Creating helpers: When to delegate work. Too Early To Say. https://tooearlytosay.com/research/methodology/spawning-agents/Copy citation