Collecting thousands of grocery store locations from Google Places API means handling: rate limits that throttle rapid requests, pagination that returns results in batches of 20, transient API errors, and the risk of losing hours of progress to an unexpected failure.
A straightforward script fails on multiple counts.
What Goes Wrong Without Robustness
A naive approach (loop through counties, query the API, append results to a list, save at the end) fails in predictable ways:
Rate limit exceeded (2:47 AM): The script hammers the API too fast. Google returns OVER_QUERY_LIMIT. The script crashes. Four hours of progress lost.
Network timeout (4:12 AM): A transient network issue during the Fresno query. The script throws an exception. Everything collected since the last save: gone.
Laptop sleeps (1:30 AM): The collection was running overnight. The laptop went to sleep. The script lost its place. Restarting means re-querying counties already completed, wasting API budget.
These aren't edge cases. They're the default outcome for any multi-hour API collection.
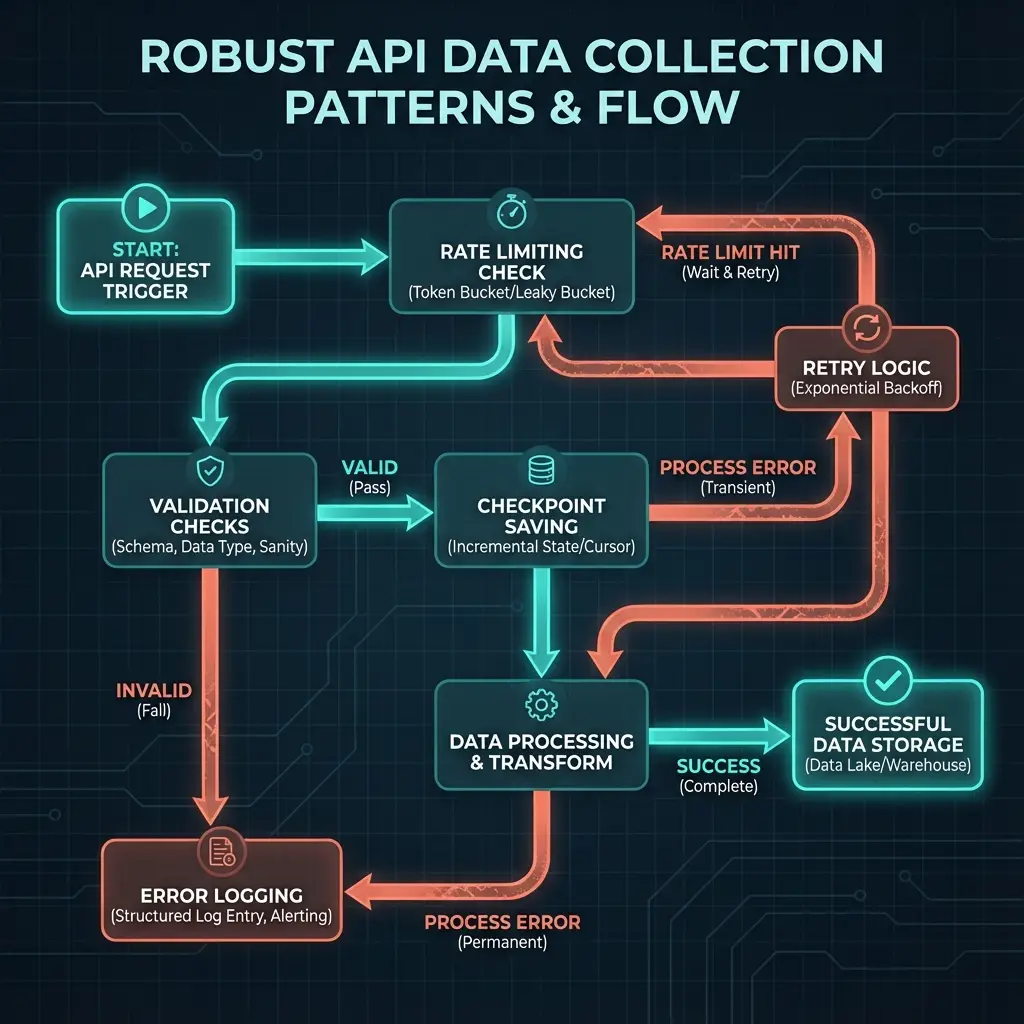
Rate Limiting
The first protection: never exceed API rate limits regardless of how fast the code runs.
@rate_limit(calls_per_second=5)
def search_places(query, location, radius):
return gmaps.places(query=query, location=location, radius=radius)A decorator pattern wraps the API call. If calls come too fast, the decorator sleeps until the rate limit window resets. The rest of the code doesn't need to know about rate limits; it just calls search_places() and the decorator handles pacing.
Checkpointing
The second protection: track progress so restarts don't mean starting over.
class CheckpointManager:
def __init__(self, checkpoint_file):
self.state = self._load()
def mark_county_complete(self, county):
self.state['completed_counties'].append(county)
self.save()
def set_progress(self, county, page_token):
self.state['current_county'] = county
self.state['page_token'] = page_token
self.save()The checkpoint file records which counties are complete and where pagination left off. When the script restarts after a crash, it reads the checkpoint and resumes from the last saved position.
In the food security collection, the script crashed at 3:47 AM during Contra Costa County (network timeout). On restart, it skipped Santa Clara, Alameda, and San Mateo (already complete), resumed Contra Costa at page 12 of 15, and continued. Total data loss: zero.
Incremental Saving
The third protection: save results continuously so crashes lose minimal work.
def save_results_incremental(stores, county, batch_num):
filename = f'{county}_batch_{batch_num:03d}.json'
with open(filename, 'w') as f:
json.dump(stores, f)Each batch of 20 results saves to disk immediately. A catastrophic failure (power outage, kernel panic, out of memory) loses at most 20 records. The alternative (save everything at the end) risks losing everything.
Error Recovery
The fourth protection: retry transient errors instead of crashing.
@retry(stop=stop_after_attempt(3), wait=wait_exponential(min=4, max=60))
def fetch_place_details(place_id):
return gmaps.place(place_id, fields=[...])Network timeouts, temporary API errors, and rate limit responses trigger automatic retries with exponential backoff. First retry after 4 seconds, second after 8, third after 16. If all three fail, then the script raises an exception, but transient errors almost always resolve on retry.
In the food security collection, 23 errors occurred over the 6-hour run. All 23 succeeded on retry. Without retry logic, 23 crashes.
Execution Results
Counties processed:
Santa Clara: 1,247 stores (completed 11:23 PM)
Alameda: 1,089 stores (completed 12:47 AM)
San Mateo: 634 stores (completed 1:32 AM)
Contra Costa: 782 stores (completed 2:28 AM)
San Francisco: 498 stores (completed 3:01 AM)
Fresno: 891 stores (completed 4:12 AM)
Kern: 762 stores (completed 5:18 AM)
Total: 6,613 stores
API cost: $147.23
Errors recovered: 23 (all successful on retry)
Checkpoints saved: 412The collection ran overnight, unattended, without data loss.
Division of Labor
Human responsibility: Which counties to query, what attributes to collect, acceptable cost bounds.
Agent responsibility: Rate limiting, checkpointing, incremental saving, retry logic, progress logging.
These are standard robustness patterns: well-documented, widely used. The agent makes implementing them correctly as fast as implementing them incorrectly. Without the agent, getting all four patterns right might take a day of debugging. With the agent, about an hour.
Cost Summary
| Item | Cost |
|---|---|
| Google Places Search API | $112.41 |
| Google Place Details API | $33.07 |
| Retry requests | $1.75 |
| Total | $147.23 |
Reasonable for research-quality location data covering seven counties. The robustness investment paid off: zero re-queries due to crashes, zero lost data, zero manual intervention overnight.
How to Cite This Research
Too Early To Say. "6,613 Stores, $147, Zero Lost Data: Robust API Collection." November 2025. https://tooearlytosay.com/research/methodology/robust-api-data-collection/Copy citation