This article brings together everything from our advanced series on AI-assisted research. Having covered agents, skills, hooks, and MCP servers individually, we now see how these pieces combine into a personal research system that becomes more valuable over time.
Think of this like building research capital. Each piece we set up - the context file, the saved workflows, the automatic checks, the data connections - makes the next piece more valuable. A researcher who has invested in this setup over six months has a significant advantage: their AI assistant knows their methods, follows their preferences, and catches common mistakes automatically.
Quick Refresher on the Components
Before we dive in, here is a brief reminder of what we covered in the previous four articles:
- Agents - A way to run tasks in parallel. Instead of waiting for one literature search to finish before starting another, we can spawn separate agent "threads" that work simultaneously.
- Skills - Saved workflows we can invoke by name. Rather than explaining our robustness check process every session, we save it once and call
/robustnesswhenever we need it. - Hooks - Automatic triggers that run without asking. When we commit code, a hook can verify citations automatically - we do not have to remember to run the check.
- MCP Servers - Connections to external data sources. Instead of opening FRED in a browser, we can ask Claude to pull the latest employment data directly.
Each component works on its own. This article shows what happens when we combine them.
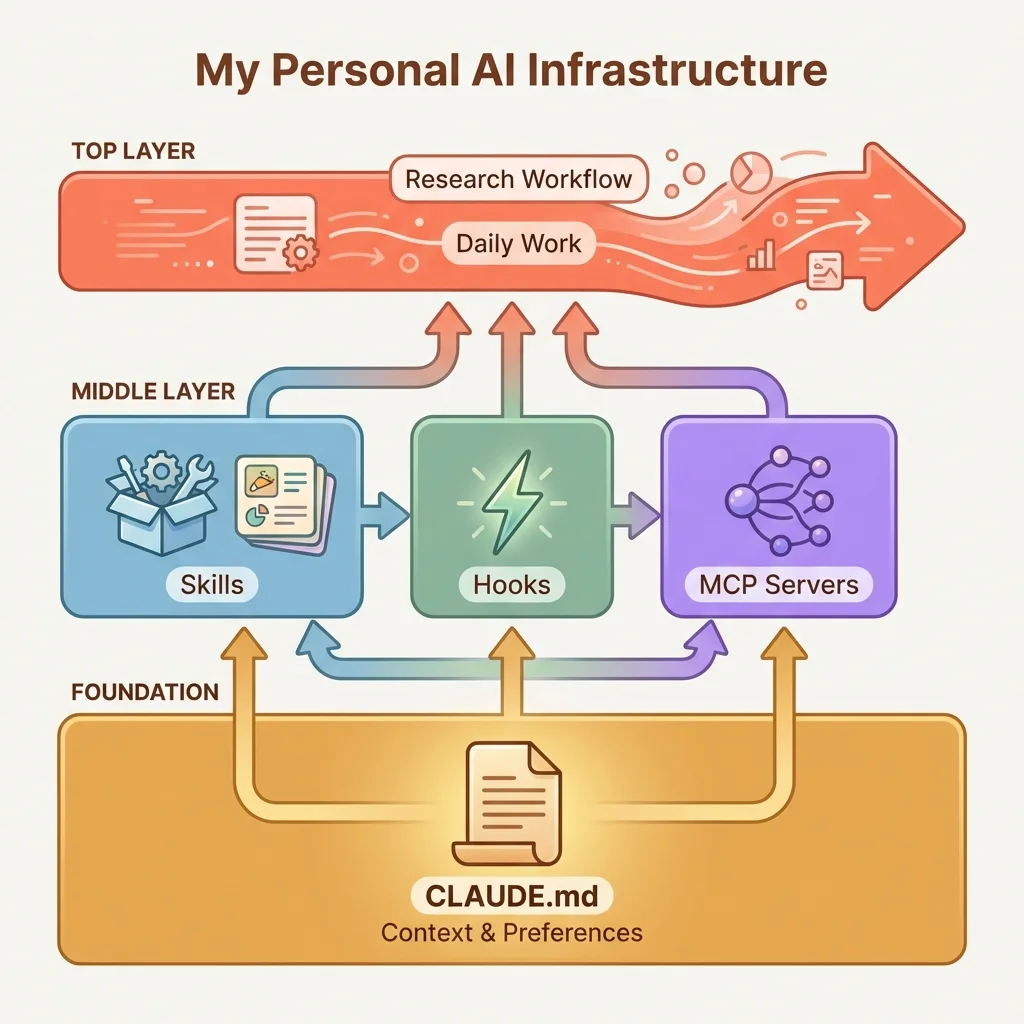
What We Will Learn
We will explore how CLAUDE.md anchors our system, how skills accumulate into a personal research library, how hooks catch the things we forget, how MCP connections reduce time switching between tools, and how the entire system improves our work over months, not just sessions.
We have covered the pieces. Now let us see how they fit together.
A CLAUDE.md file that knows our identification strategy. Skills that encode our research workflows. Hooks that run verification checks we would otherwise forget. MCP servers that connect us to the data sources we actually use. Each piece solves a specific problem. But the real power emerges when they work as a system.
This is what we mean by a personal research system: a set of components that become more valuable over time, making each research session more productive than the last. The investment compounds, much like research experience itself.
CLAUDE.md as Foundation
Everything builds on context. Without knowing which paper we are writing, what our identification strategy is, and which variables we are tracking, every other component operates blind.
The CLAUDE.md file anchors everything else. It solves the cold start problem we covered in the Intermediate tier, but it does more than that. It becomes the reference point for skills, hooks, and integrations.
What belongs in global CLAUDE.md
Our global file (at ~/.claude/CLAUDE.md) captures preferences that span projects:
- Citation style preferences (APA, Chicago, journal-specific)
- Stata/R/Python coding conventions we follow
- Verification practices we want enforced across all papers
- Author identity and co-author information
What belongs in project-specific CLAUDE.md
Each paper's file captures context specific to that research:
# Current Paper: Labor Market Effects of Minimum Wage
## Identification Strategy
- Difference-in-differences with staggered adoption
- Treatment: State minimum wage increases 2015-2022
- Control: Bordering counties in non-adopting states
- Key assumption: Parallel trends in employment pre-treatment
## Key Variables
- Outcome: Log quarterly employment (QCEW)
- Treatment: Binary indicator for MW increase > $1
- Controls: County population, industry mix, unemployment rate
## Current Status
- Draft 3, addressing R1 comments from JHR
- Reviewer concern: Spillover effects to control counties
- Next step: Implement Callaway-Sant'Anna estimator
## Data Sources
- QCEW: Quarterly, county-level, 2010-2023
- ACS: Annual demographic controls
- DOL: State minimum wage historyKeeping it current as papers progress
As we move from exploratory analysis to draft to revision, the CLAUDE.md should reflect that progression. When we receive reviewer comments, we document them. When we add a robustness check, we note it. The context file becomes a living research log.
The pattern that works: update CLAUDE.md whenever the paper's focus shifts. This way, every session knows where we are in the research process.
Skills Library
Skills encode workflows we run repeatedly. One skill saves time once. A library of skills changes how we conduct research.
Building a library of reusable workflows
Over months of research, patterns emerge. We find ourselves explaining the same process to Claude over and over: how to structure a literature review, how to document robustness checks, how to prepare a replication package. Each repeated explanation is a skill waiting to be created.
Start with the workflows we do most often:
/lit-search- Systematic paper gathering with citation verification/robustness- Standard robustness check battery with documentation/data-doc- Data documentation template for replication/replication-package- Prepare code and data for journal submission
Then add domain-specific skills:
/parallel-trends- Visual and statistical parallel trends diagnostics/event-study- Event study specification with proper leads and lags/sensitivity- Sensitivity analysis for selection on unobservables
Organizing skills by research phase
As the library grows, organization matters. We might structure skills by where they fall in the research process:
.claude/skills/
data/
data-doc.md
merge-check.md
balance-table.md
analysis/
parallel-trends.md
event-study.md
robustness.md
sensitivity.md
writing/
lit-review.md
results-section.md
limitations.md
submission/
replication-package.md
response-letter.md
revision-tracker.mdVersion control for skills
Skills are methodology. They evolve as our research practices improve. Keeping them in version control means we can track what changed, roll back mistakes, and maintain consistency across papers.
The compound effect
The first skill takes effort to create. The tenth skill builds on patterns from the first nine. By the twentieth skill, we have encoded our research methodology in files. New papers start with infrastructure that reflects how we actually work.
Hooks for Automation
Skills require invocation. Hooks run automatically.
The difference matters. Some things we should always do: verify citations before committing, log analysis commands for replication, check that data documentation exists. These are not optional steps we might choose to skip. They are requirements that should happen without asking.
Hook triggers for common failure points
Where do things go wrong in research? Those are hook opportunities:
- Pre-commit: We forget to verify that cited papers actually exist. A citation verification hook catches this.
- Analysis patterns: We run a regression but forget to log it for replication. An analysis logging hook captures commands automatically.
- Data access: We reference a dataset but the documentation file is missing. A data documentation hook flags undocumented sources.
- Session end: We close the session without updating the paper's status in CLAUDE.md. A session-end hook prompts for capture.
Building hooks that invoke skills
Hooks and skills work together. A hook detects a condition. A skill handles the response.
Example: A pre-commit hook detects that we have added citations to the manuscript. Instead of duplicating verification logic in the hook, it invokes the /citation-verify skill. The skill checks DOIs, confirms author-title matches, and reports results. The hook decides whether to allow the commit based on the skill's output.
This separation keeps hooks simple (detection) and skills comprehensive (execution).
The confidence of knowing checks will run
When hooks are in place, we stop worrying about forgotten steps. The infrastructure catches what we miss. We can focus on the research itself, trusting that the system will flag problems before they become costly reviewer objections.
MCP Integrations
CLAUDE.md gives us context. Skills give us workflows. Hooks give us automation. MCP servers give us reach.
Without MCP, Claude Code works with files and commands. With MCP, it connects to the data sources and tools we actually use: FRED for macroeconomic data, Census APIs for demographic variables, Google Scholar for literature verification, Zotero for reference management.
Connecting to the data sources we actually use
The daily workflow for an applied economist touches many systems:
- Check FRED: Has the latest employment data been released?
- Check Census: Pull updated ACS estimates for our control variables
- Check Scholar: Verify that a citation is correct and find related papers
- Check Zotero: Ensure our bibliography is synchronized
Without MCP, each check requires switching contexts, opening browsers, navigating APIs manually. With MCP, a single prompt can gather information from all these sources.
The research workflow
Imagine starting a session with:
"Morning check: pull the latest QCEW release date from FRED, list any new papers citing our baseline study on Scholar, and flag any bibliography entries that don't appear in the manuscript."
With the right MCP servers configured, Claude executes this in one pass. We get the information organized for our review without opening four different tools.
Reducing context switches
Every context switch has a cost. Opening the FRED interface, navigating to the right series, downloading the data, returning to Stata. MCP integrations keep us in the flow. The data comes to us rather than us going to the data.
Building custom integrations for research needs
The available MCP servers cover common cases: Google Analytics, Stripe, Sentry. But research workflows have specialized needs. We might need to connect to:
- IPUMS (Integrated Public Use Microdata Series) for harmonized census microdata
- BLS (Bureau of Labor Statistics) for establishment-level data
- State administrative records via secure APIs (Application Programming Interfaces)
- University HPC (High-Performance Computing) clusters for computation
Custom MCP servers let us extend Claude's reach to any data source with an API. The effort is front-loaded, building the server once, but the payoff continues for every future paper.
The Compound Effect
Each piece adds value. Together, they multiply it.
CLAUDE.md + skills = context-aware retrieval
The context file tells skills about our current paper. When we invoke /robustness, the skill knows which specifications to check from CLAUDE.md. When we invoke /lit-search, the skill focuses searches on terms relevant to our research question. Skills become context-aware automatically.
Skills + hooks = reliable verification
Skills define what checks to run. Hooks decide when to run them. The combination means verification happens at the right moments without manual invocation. We create the methodology once and it applies across papers.
Hooks + MCP = deeply integrated research systems
Hooks can invoke MCP tools. A morning-start hook might check FRED for data updates automatically. A pre-submission hook might verify all citations against Google Scholar. The automation extends beyond local files to external data sources.
CLAUDE.md + skills + hooks + MCP = infrastructure that knows our research methodology
After six months with this system, research sessions feel different. We spend less time on setup and verification. We catch data issues earlier. External sources integrate smoothly into our workflow. The accumulation is real: each week of investment makes future papers more productive.
Think of this like the difference between a new faculty member setting up a lab and an established researcher with systems already in place. The established researcher can focus on the science because the operational pieces are solved.
Building systems requires looking across projects
The pieces we have discussed (CLAUDE.md, skills, hooks, MCP) become a system only when we look for patterns across our research rather than within a single paper.
Consider how skills emerge. We run a robustness check battery for one paper. Then we run a similar battery for another paper. Then a third. At some point, we notice the pattern: we always check parallel trends, test for sensitivity to controls, examine treatment effect heterogeneity. The pattern across papers becomes a skill that applies to future papers.
The same logic applies to hooks. If we forgot to verify citations once, that is a mistake. If we forgot three times across three papers, that is a pattern worth automating. If we consistently need FRED data at the start of analysis sessions, that is an MCP integration worth building.
System-building requires zooming out. The question is not "what workflow helps this paper?" but "what workflow appears across my research?" The answer points to infrastructure worth investing in.
This is harder than it sounds. We are trained to focus on the current project. But the compound value of infrastructure comes from recognizing repeating patterns and encoding them once, then reusing forever.
Maintaining the System
Infrastructure requires maintenance. Left alone, it becomes stale.
Regular review: what is working, what is stale
Set a monthly checkpoint. Review:
- Which skills are we actually using?
- Which hooks are firing and helping?
- Which MCP integrations are valuable?
- What is in CLAUDE.md that no longer applies?
The answers guide maintenance.
Updating context as papers progress through drafts
Papers move through stages: exploratory analysis, first draft, revision, resubmission. The CLAUDE.md should reflect the current stage.
What matters during exploratory analysis (data sources, variable definitions) differs from what matters during revision (reviewer concerns, specific robustness checks requested). Update the context to match the phase.
The heuristic: if we have not used a skill in three months, archive it. If CLAUDE.md mentions a dataset we no longer use, update it. If a hook never fires, question whether it is needed.
Updating hooks as research evolves
Our methods change. The hooks should change with them. A hook created for one paper's identification strategy might become irrelevant for the next paper. A hook that was too aggressive might need tuning. A hook that missed cases might need expansion.
Review hook effectiveness during maintenance. Are they catching real problems? Are they creating noise? Adjust accordingly.
Adding new integrations as needs emerge
New tools enter our workflow. New services become important. MCP integrations should grow with our needs.
When we find ourselves repeatedly downloading data manually, that is a signal. Can we bring that data into Claude via MCP? The effort of building or configuring the integration pays off in reduced friction.
The maintenance tax vs. the productivity dividend
Maintenance takes time. There is no avoiding it. But the productivity dividend from well-maintained infrastructure far exceeds the maintenance cost.
A rough accounting: spending two hours monthly on infrastructure maintenance saves ten hours of friction across research sessions. The math favors investment.
The warning: do not over-build
There is a trap in the excitement of building infrastructure. We create skills for every possible workflow. We add hooks for every conceivable check. We connect MCP servers for data sources we might someday use. The system grows complex, and complexity has costs.
The maintenance burden compounds. Skills need updating as our methods evolve. Hooks fire on false positives and slow our workflow. MCP connections break when APIs change. What started as productivity infrastructure becomes productivity drag.
The discipline: build only what we use this month. If we have not invoked a skill in three months, archive it. If a hook has never caught a real problem, question whether it belongs. The system should be as small as it can be while still serving our actual research.
This is hard advice for those who enjoy building systems. The temptation is to prepare for every contingency. But unused infrastructure is not an asset: it is maintenance liability waiting to consume our attention.
Where to Go From Here
This article completes the Advanced tier, but it opens more than it closes.
Advanced skill patterns
Skills can chain: the output of one feeds the input of another. A /data-doc skill might feed into a /replication-package skill. Skills can be conditional: different execution paths based on whether we are doing exploratory analysis or preparing for submission. Skills can spawn agents: delegating sub-tasks like literature search to parallel contexts.
These patterns enable complex workflows that would be tedious to invoke manually.
Hook composition
Hooks can invoke hooks. A master pre-commit hook might orchestrate multiple specialized hooks: citation verification, code documentation, data provenance checks. A session-end hook might trigger different capture routines based on what changed.
Composition creates layered automation that handles complex scenarios gracefully.
Custom MCP servers for specialized data
If we work with specialized data sources, custom MCP servers become worthwhile. The Model Context Protocol is open. Building servers that connect Claude to administrative data, proprietary databases, or HPC systems extends the infrastructure in powerful ways.
Contributing to the ecosystem
Skills and MCP servers can be shared. What we build for our research might help other economists with similar workflows. The ecosystem grows when practitioners contribute what works.
The long game
Personal AI infrastructure is an investment with increasing returns. The system we build today makes the next paper easier. The patterns we encode now apply to future projects. The integrations we configure once serve every research session.
Over months and years, this compounds. The gap between productive AI collaboration and frustrating trial-and-error widens. The productive side becomes ours because the infrastructure supports our methodology.
Practical Recommendations
- Start with CLAUDE.md. Everything else builds on context. If we do not have a current context file documenting our research project, that is the first investment.
- Create skills for the top three repeated workflows. We do not need a comprehensive library on day one. Start with what we do most often: literature review, robustness checks, data documentation.
- Add one hook for our most common failure. What do we forget most frequently? Citation verification? Analysis logging? Automate catching that.
- Configure one MCP integration for daily use. Pick the external data source we access most often. Bring it into Claude.
- Schedule monthly maintenance. Put it on the calendar. Review what is working and prune what is not.
- Document as we build. The infrastructure should describe itself. Skills with clear purposes. Hooks with documented triggers. CLAUDE.md that maps the whole system.
The system we build serves us across papers and over time. It accumulates value. The earlier we start, the more we benefit.
This Is Achievable
A final note for readers who have made it this far but still feel uncertain about the technology: this is achievable for non-programmers.
The components we have discussed do not require software engineering expertise. CLAUDE.md is just a text file. Skills are written descriptions of our research procedures - the same explanations we would give a research assistant. Hooks are simple triggers, not complex code. MCP connections often require just configuration, not programming.
The learning curve is real but manageable. Start small. Add one piece at a time. Each piece we add works immediately - we do not need the complete system before seeing benefits.
Many applied economists have built exactly these systems while knowing little about software development. The skills they brought were research methodology and clear thinking about their workflows. Those are the skills that matter.
If we can explain our research process to a colleague, we can teach it to Claude. That is what this system is: a way to capture what we know so the AI assistant can help us consistently.
We do not need to become programmers. We just need to write down what we already know.
Series Complete
This concludes the Claude Code Guide - Advanced Tier and the complete 13-article series.
Full Series Curriculum
Beginner Tier (3 Articles)
- 1. Your First Session: What Claude Code Is and Isn't
- 2. Why It Forgot Everything: Understanding Context
- 3. Reading Our Analysis Files: How Claude Sees Our Research Code
Intermediate Tier (5 Articles)
- 4. The Cold Start Problem
- 5. End-of-Session Hygiene
- 6. Context Window Budgeting
- 7. The Verification Tax
- 8. Research Phases Need Different Prompts
Advanced Tier (5 Articles)
- 9. Spawning Agents: When to Delegate
- 10. Creating Skills: Reusable Workflows
- 11. Hooks: Automation Without Asking
- 12. MCP Servers: Extending What Claude Can Do
- 13. Building Our Research System: Putting It All Together
The Beginner tier teaches what Claude Code is and how it sees our work. The Intermediate tier teaches session discipline: how to start warm, end clean, manage tokens, verify outputs, and prompt by phase. The Advanced tier teaches system building: how to spawn agents, create skills, automate with hooks, extend with MCP, and combine everything into infrastructure that compounds.
Together, these 13 articles form a complete curriculum for AI-assisted research. The practices scale from first session to long-term workflow.
Suggested Citation
Cholette, V. (2026, March 25). Building our research system: Putting it all together. Too Early To Say. https://tooearlytosay.com/research/methodology/personal-ai-infrastructure/Copy citation