Staying current with academic literature is simple in theory and tedious in practice. Open SSRN. Search. Scroll. Open NBER. Browse. Scroll. Open Google Scholar. Search. Scroll. Note anything interesting. Repeat next week. The searches take maybe 30 minutes when done properly, which means they often get abbreviated or skipped entirely when deadlines loom.
Several free tools already automate pieces of this work. Combining them into a single workflow, and verifying what they produce, is where an AI coding assistant earns its keep.
What already exists
Here is what is freely available today:
| Tool | What it does | Limitation |
|---|---|---|
| Google Scholar alerts | Emails new papers matching a keyword query | Keyword-only; no citation network traversal; no API |
| Semantic Scholar API | Free API covering 200M+ papers with citation data, recommendations | Does not cover SSRN preprints or NBER working papers directly |
| Connected Papers | Visual graph of related papers from a seed paper | Limited free tier; manual one-paper-at-a-time exploration |
| Litmaps | Timeline visualization of citation networks | Similar to Connected Papers; free tier limited |
| Research Rabbit | AI-powered recommendations from collections | Requires building collections manually |
Each of these handles part of the problem. Google Scholar alerts catch new papers by keyword. Semantic Scholar provides structured citation data. Connected Papers and its equivalents visualize how papers relate to each other through citation networks.
None of them combine all three academic sources (SSRN for preprints, NBER for economics working papers, Google Scholar or Semantic Scholar for published work), deduplicate across them, or verify that the citations they surface are accurate.
What the AI assistant adds
The assistant acts as glue. It can:
-
Query multiple sources in one pass. Search SSRN via browser automation, download NBER’s weekly metadata files (CSV format, freely available at nber.org/research/data), and query the Semantic Scholar API. Three sources, one command.
-
Follow citation networks from seed papers. Given 2-3 known papers, the assistant extracts their reference lists (backward expansion) and searches for papers that cite them (forward expansion via Semantic Scholar’s citation API). Two levels of expansion from three seed papers can surface 50-100 unique works. This is the same pattern that Connected Papers uses, automated across sources rather than limited to one tool’s index.
-
Deduplicate across sources. The same paper often appears on SSRN, in the NBER series, and in Semantic Scholar. The assistant matches on title similarity and author-plus-year to produce a single list of unique papers with notes on which sources carried each one.
-
Run on a schedule. Most AI coding assistants now support scheduled execution. Setting the scan to run weekly against a set of search queries produces a rolling digest of new papers, replacing the manual “remember to check this week” discipline.
The browser automation layer (Chrome DevTools in the case of Claude Code) handles the sources that lack APIs. SSRN does not offer a public search API, so the assistant navigates to the search page, enters terms, and extracts results from the rendered page. This is slower than an API call but reliable for the volume of results a weekly scan produces (typically 10-30 new papers per query).
NBER does not have a search API either, but provides something better for monitoring: downloadable metadata files updated weekly. The assistant fetches the CSV, filters by date and topic keywords, and extracts matching papers. No scraping needed.

How the automation fails
The useful part of this article is not the automation. Automation is straightforward. The useful part is knowing how the automation fails.
Hallucinated papers. The assistant generates a citation that does not exist. The title sounds plausible. The authors are real researchers in the field. The journal name is real. But the paper was never written. The DOI, if one is provided, resolves to nothing or to an entirely different paper.
This happens when the assistant draws on patterns in its training data rather than actually searching a database. The fix is architectural: instruct the assistant to search a specific source (Semantic Scholar API, SSRN search results, NBER metadata file) and extract results from the response. Never let it generate citations from memory.
Misattributed claims. The assistant cites a real paper but attributes a finding to it that the paper does not contain. The paper exists, the authors are correct, the journal and year are right, but the specific claim (“found a 38% reduction in emergency department visits”) appears nowhere in the text.
This is harder to catch than outright hallucination because the citation metadata checks out. The paper is real. The error is in what the paper supposedly says. In one verification pass across 45 references in a policy report, six had errors of this kind: fabricated authors, DOIs resolving to wrong papers, and claims that did not appear in any published version of the cited work.
Author swaps. Two researchers in the same subfield get crossed: a paper by Author A gets attributed to Author B, who works on similar topics. The title and journal are correct; the byline is wrong.
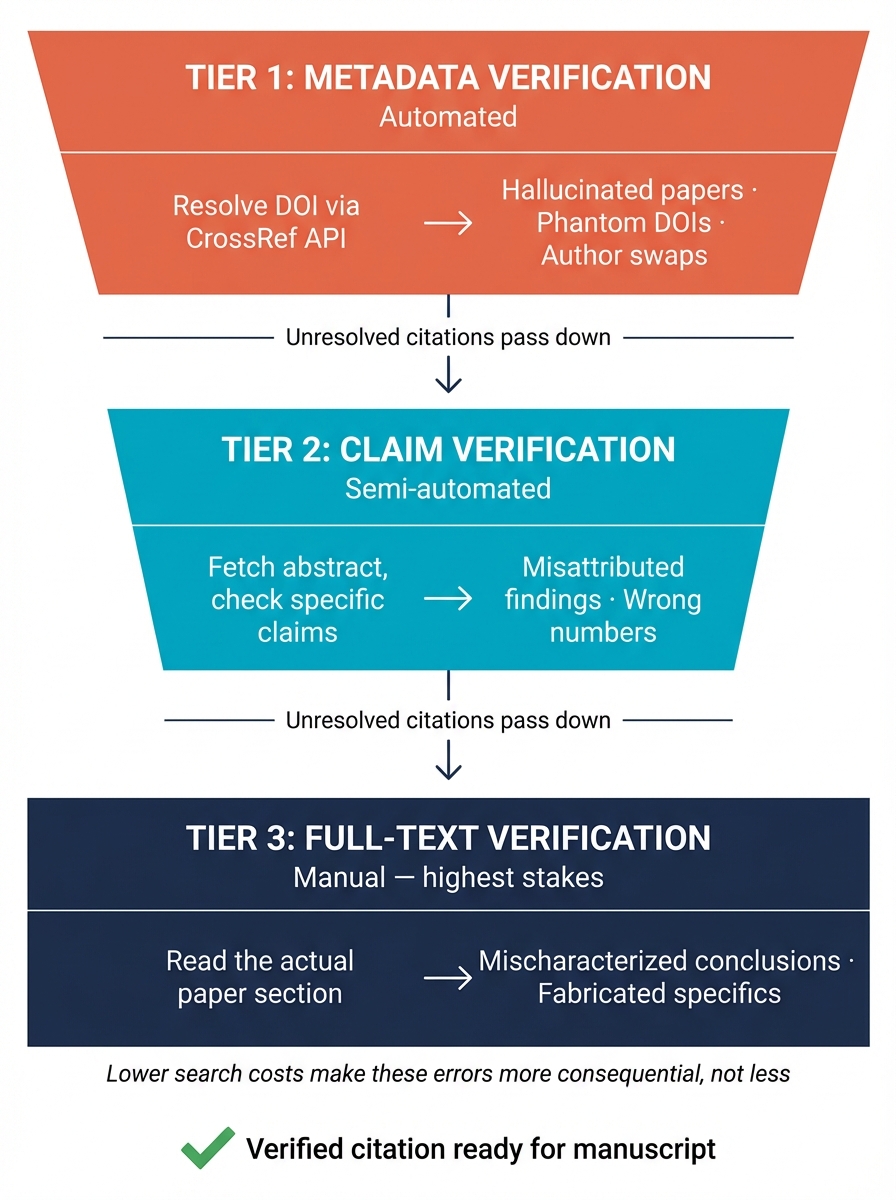
A three-tier verification process
The solution is to treat every AI-surfaced citation as unverified until checked. The verification has three tiers, each catching a different class of error.
Tier 1: Metadata verification (automated). For each citation, resolve the DOI through the CrossRef API. Check that the returned title, authors, year, and journal match the claim. This catches hallucinated papers (DOI does not exist), phantom DOIs (DOI resolves to wrong paper), and author swaps (returned authors do not match).
For each citation in [file], resolve the DOI via
CrossRef. Compare the returned title, authors, year,
and journal against what the citation claims. Flag
any mismatch. For citations without DOIs, search
CrossRef by title and first author.
Tier 2: Claim verification (semi-automated). For each specific claim attributed to a citation (“found a 38% reduction,” “estimated an AUC of 0.83”), fetch the abstract from PubMed or the publisher. Search for the specific numbers or findings.
For each citation that includes a specific numerical
claim, fetch the abstract. Check whether the claimed
finding appears. If not, flag for manual full-text
review.
Abstracts do not contain every finding, so a missing match does not prove the claim is wrong. But it flags claims that need a closer look.
Tier 3: Full-text verification (manual, highest stakes). For claims central to the argument that could not be verified from the abstract, read the relevant section of the actual paper. “Subtle” does not mean unimportant. Mischaracterized conclusions and fabricated specifics that pass Tiers 1 and 2 are often the most consequential errors, precisely because they attach to real, correctly cited papers. Lower search costs across the other dimensions make Tier 3 more important, not less: the easier it becomes to gather citations, the more critical it becomes to verify what those citations actually say.
The three tiers form a funnel: Tier 1 is cheap and catches fabrications. Tier 2 catches misattributions. Tier 3 is expensive per citation but is where the highest-stakes errors hide.
What this replaces
The tools listed at the top of this article (Google Scholar alerts, Semantic Scholar, Connected Papers, Research Rabbit) proved the concept: literature monitoring can be automated, and citation networks are the right structure for discovery. Each tool handles a piece of the workflow well.
An AI coding assistant consolidates all of them into a single system. It searches SSRN, downloads NBER metadata, queries the Semantic Scholar API, follows citation chains in both directions, deduplicates across sources, and runs verification tiers on the output. Once that workflow is running, there is no reason to maintain separate Google Scholar alerts, a Connected Papers bookmark, and a Research Rabbit collection alongside it. The assistant does what those tools do, in one pass, with verification built in.
The prior tools become reference points rather than active parts of the workflow. Connected Papers is still useful for a quick visual exploration of one paper’s neighborhood. Google Scholar alerts still work for someone who prefers email notifications. But for a research team that has invested in an AI coding assistant, those tools are training wheels that the consolidated workflow outgrows.
The manual workflow: 30-60 minutes per week, often skipped.
The automated workflow: runs on a schedule, 5-10 minutes to review the digest, plus verification time for any citations entering a manuscript.
As far as our experience goes, and acknowledging that every tool has features beyond what any single user exercises, this workflow replaces those standalone services in their current form. The assistant does what they do, combines what they cannot combine on their own, and adds a verification layer none of them offer.
The value is consolidation (one system instead of five), reliability (the scan happens every week regardless of deadline pressure), and a verification discipline that none of the standalone tools provide.
Cite this article
Cholette, V. (2026, April 6). building a Literature Surveillance System. Too Early To Say. https://tooearlytosay.com/research/methodology/literature-surveillance-skill/