Google Places API returns thousands of results for "grocery store" across California counties. The results include supermarkets like Safeway and Trader Joe's, but also 7-Eleven locations, gas station minimarts, liquor stores, and restaurants with incidental grocery items.
For food access research, this distinction matters. A convenience store does not provide equivalent food security value to a full-service supermarket. Manual validation of thousands of locations is not feasible. Automated classification becomes necessary.
The Training Data
400 labeled locations (200 confirmed grocery stores, 200 confirmed non-grocery: convenience stores, liquor stores, miscategorized restaurants) provide enough training data for a binary classifier. The labeling takes about two hours: checking each location against its business website and Google Street View imagery.
Google Places provides several features for each location:
| Feature | Example Values |
|---|---|
| Business name | "Safeway" vs. "QuickStop" |
| Type tags | "supermarket," "convenience_store" |
| User rating | 1-5 scale |
| Review count | 12 vs. 847 |
| Price level | $ to $$$$ |
Our hypothesis: real grocery stores tend to have certain type tags, higher review counts, and names containing words like "market" or "foods" rather than "liquor" or "gas."
Model Iteration
With a labeled dataset, Claude Code can iterate through classifier specifications rapidly. Each cycle (write code, run it, evaluate accuracy, propose modifications) takes minutes rather than hours.
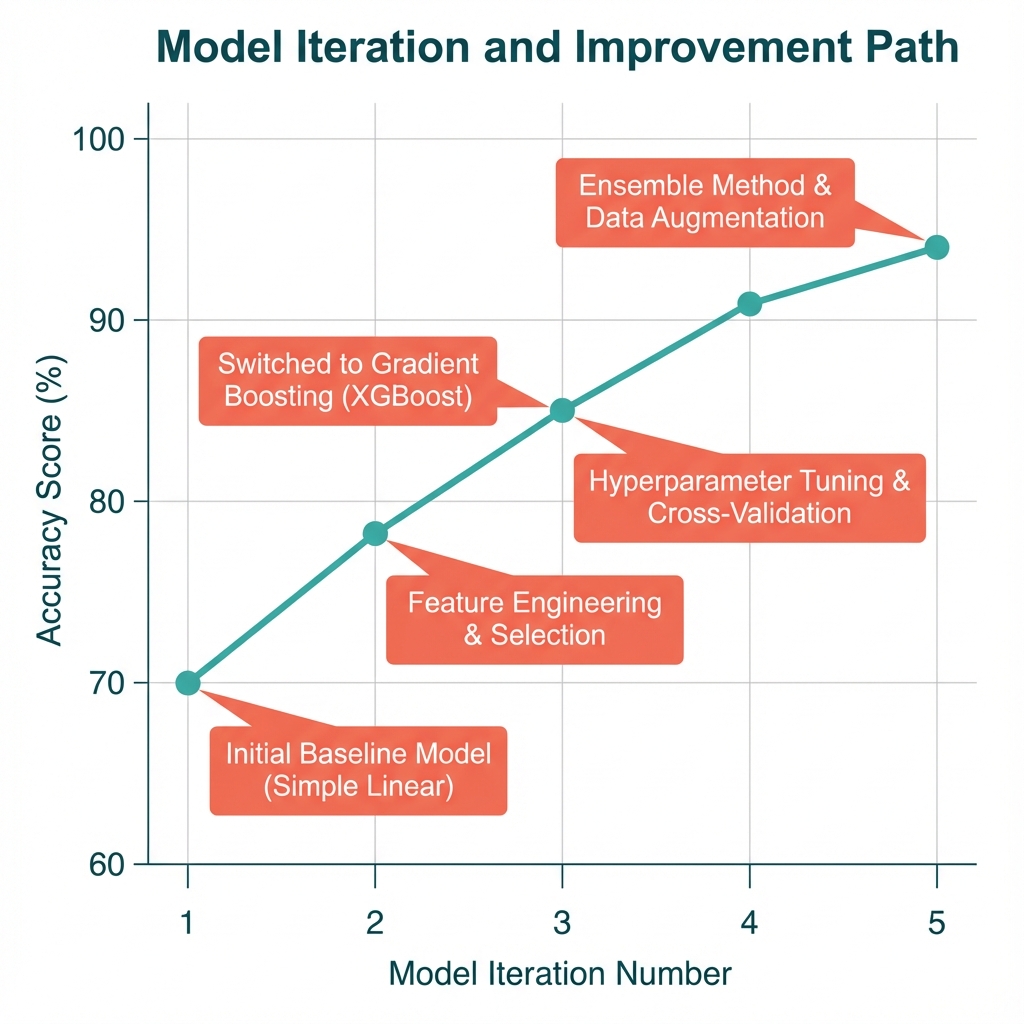
Iteration 1: Logistic regression, raw features
→ 78% accuracy
Iteration 2: Added text features from business names
(name_has_market, name_has_liquor, name_has_gas)
→ 84% accuracy
Iteration 3: Parsed Google type tags into binary indicators
→ 88% accuracy
Iteration 4: Added review count interaction terms
→ 91% accuracy
Iteration 5: XGBoost with tuned hyperparameters
→ 94% balanced accuracyThe jump from 78% to 84% came from a simple observation: business names contain signal. "Safeway" and "Trader Joe's" differ systematically from "7-Eleven" and "Chevron Food Mart." Extracting indicator variables for common substrings captures this.
The final jump to 94% came from switching to XGBoost, which handles feature interactions better than logistic regression. Review count matters more for locations tagged as "convenience_store" than for those tagged as "supermarket." A large convenience store with hundreds of reviews might actually be a grocery store miscategorized by Google.
What the Model Learned
Feature importance analysis reveals which signals drive predictions:
| Feature | Importance |
|---|---|
| type_supermarket | 0.31 |
| type_convenience_store | 0.22 |
| log_review_count | 0.15 |
| name_has_liquor | 0.09 |
| name_has_market | 0.08 |
| price_level | 0.06 |
| user_rating | 0.05 |
| name_has_gas | 0.04 |
The type tags dominate, which makes sense: Google's categorization captures real information. But name-based features add predictive power, especially for edge cases where Google's tags are ambiguous or missing.
Validation
When we spot-check 50 predictions from each category against business information, we find:
- Predicted grocery, actually grocery: 47/50 (94%)
- Predicted non-grocery, actually non-grocery: 48/50 (96%)
The three false negatives were ethnic markets with non-English names that lacked the typical "market" or "grocery" substrings. The two false positives were large convenience stores (a Walgreens and a CVS) that arguably do provide meaningful food access; the classification boundary is genuinely ambiguous here.
Results
Applied to the full 6,613 locations: 4,847 classify as grocery stores (73%), 1,766 as non-grocery (27%).
Without classification, grocery access would be overstated by approximately 27%. The spot-check suggests roughly 6% misclassification remains, but this is acceptable for research purposes: the alternative is either manual review of 6,613 locations or no validation at all.
Time Investment
| Task | Time |
|---|---|
| Manual labeling (400 locations) | 2 hours |
| Model iteration with Claude Code | 1.5 hours |
| Validation spot-checks | 1 hour |
| Total | 4.5 hours |
Without agent-assisted iteration, this work would require 2-3 days: learning the scikit-learn API, debugging feature engineering code, manual hyperparameter tuning. The agent compresses the implementation bottleneck; the human time investment is almost entirely labeling and validation.
All code and data acquisition instructions are available in the GitHub repository.
How to Cite This Research
Too Early To Say. "400 Labels to 94% Accuracy: Validating Grocery Store Data." October 2025. https://tooearlytosay.com/research/methodology/grocery-store-classifier-validation/Copy citation