After three months of iterative analysis, a research project directory might contain 47 Python scripts with names like analysis_final_v2_FIXED.py. No documentation exists for dependencies between scripts or the order in which they should execute.
Basic questions become unanswerable: Which version produces current results? What order should scripts run? Which data files are inputs versus intermediate outputs?
The Starting Point
food_security/
├── analysis.py
├── analysis_v2.py
├── analysis_final.py
├── analysis_final_FIXED.py
├── census_data.py
├── census_data_new.py
├── clean_stores.py
├── clean_stores_backup.py
├── transit_calc.py
├── transit_calc_WORKING.py
└── ... (37 additional files)The naming tells a story: analysis.py was the original, analysis_v2.py added features, analysis_final.py was supposed to be done, analysis_final_FIXED.py patched a bug discovered later. But which one actually runs? Which produces the current results file?
Dependency Mapping
Claude Code can trace data flow through all scripts. It reads every file, identifies import statements and file I/O operations, and builds a dependency graph:
ACTIVE SCRIPTS (15):
- clean_stores.py → stores_cleaned.csv
- census_data_new.py → census_merged.csv
- transit_calc_WORKING.py → transit_times.csv
- analysis_final_FIXED.py → results.csv
DEPRECATED (32):
- analysis.py: Original version, superseded
- analysis_v2.py: Superseded by analysis_final
- analysis_final.py: Contains bug at line 234 (division by zero when tract has no stores)
- census_data.py: Uses obsolete variable names (renamed in ACS 2022)
- transit_calc.py: References stores_raw.csv, which no longer exists
- clean_stores_backup.py: Identical to clean_stores.py (SHA256 match)Only 15 of 47 scripts turn out to be required for current analysis. The remainder are obsolete versions, backups, or broken code that would fail if executed.
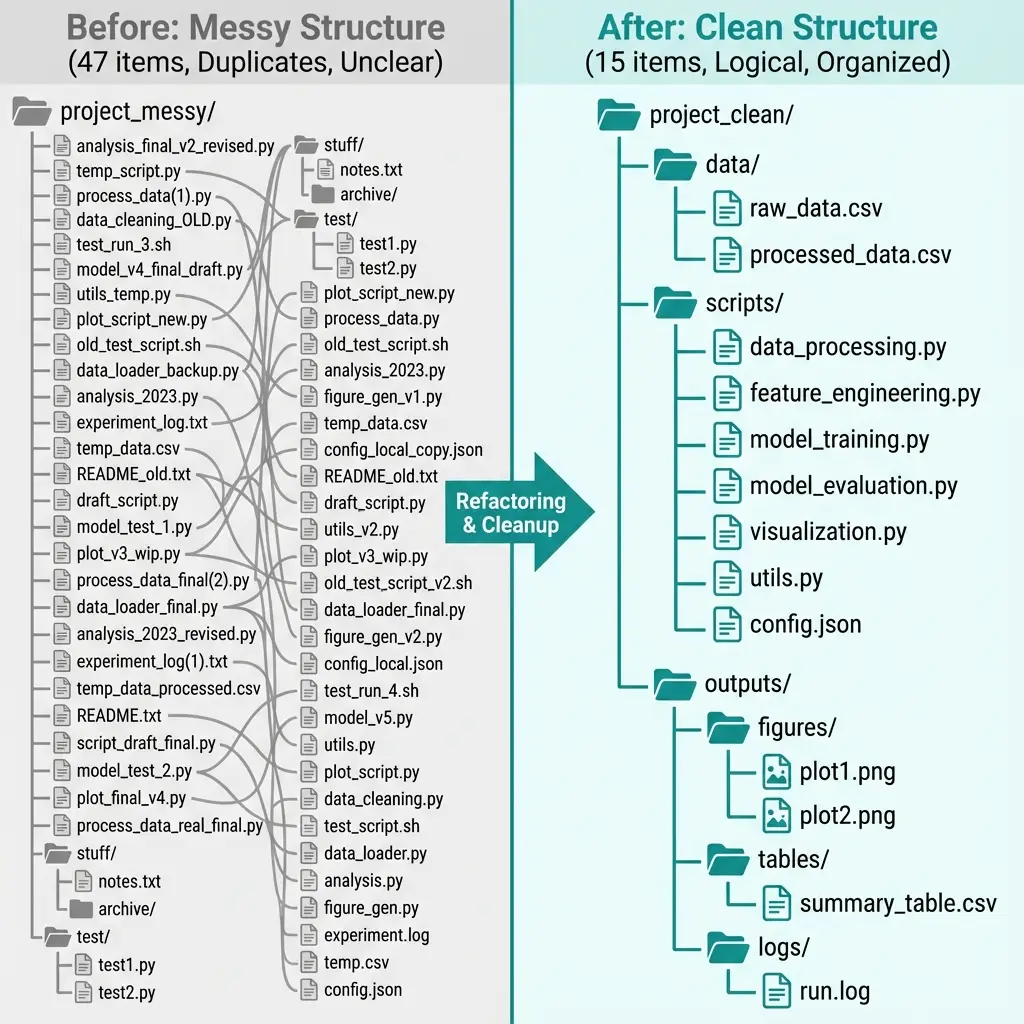
The Reorganized Structure
food_security/
├── README.md
├── CLAUDE.md
├── data/
│ ├── raw/ # Immutable source data
│ ├── processed/ # Cleaned intermediate files
│ └── output/ # Final results
├── scripts/
│ ├── 01_download_census.py
│ ├── 10_clean_stores.py
│ ├── 20_process_census.py
│ ├── 30_calculate_transit.py
│ ├── 40_calculate_vulnerability.py
│ └── 50_generate_figures.py
├── src/ # Shared utility functions
└── archive/ # Deprecated code (preserved)Numbered prefixes indicate execution order. The gaps (01, 10, 20...) leave room to insert new scripts without renumbering everything. The data directory structure distinguishes inputs from outputs: raw/ is never modified, processed/ holds intermediate files, output/ contains final results.
What Gets Updated
The reorganization touches nearly everything:
- 47 files moved to appropriate locations
- 15 active scripts renamed with numbered prefixes
- 89 import statements updated to reflect new paths
- Duplicated utility code extracted into
src/utils.py - README.md generated with project overview
- CLAUDE.md generated with data conventions for future agent sessions
Designing the Counterfactual Test
Reorganization should change file locations and names without changing analytical results. But how do you verify this? The question is fundamentally counterfactual: "What would the output be if I hadn't reorganized?"
The test design:
- Before reorganization: Run the full pipeline, save all output files, compute SHA256 hashes
- Reorganize: Move files, rename scripts, update imports
- After reorganization: Run the pipeline again, compute SHA256 hashes of outputs
- Compare: Hashes should match exactly
This works because the reorganization shouldn't change any computation: only file paths. If hashes differ, something broke.
Before reorganization:
results.csv: SHA256 = 7f83b1657ff1fc53b92dc18148a1d65dfc2d4b1fa3d677284addd200126d9069
vulnerability_scores.csv: SHA256 = 3a7bd3e2360a3d29eea436fcfb7e44c735d117c42d1c1835420b6b9942dd4f1b
figures/map_vulnerability.png: SHA256 = 2c26b46b68ffc68ff99b453c1d30413413422d706483bfa0f98a5e886266e7ae
After reorganization:
data/output/results.csv: SHA256 = 7f83b1657ff1fc53b92dc18148a1d65dfc2d4b1fa3d677284addd200126d9069 ✓
data/output/vulnerability_scores.csv: SHA256 = 3a7bd3e2360a3d29eea436fcfb7e44c735d117c42d1c1835420b6b9942dd4f1b ✓
data/output/figures/map_vulnerability.png: SHA256 = 2c26b46b68ffc68ff99b453c1d30413413422d706483bfa0f98a5e886266e7ae ✓All hashes match. The reorganization preserved analytical results.
When Hashes Don't Match
In an earlier attempt, the vulnerability map hash differed. Investigation revealed the cause: the figure-generation script used plt.savefig() with default settings, which embeds a timestamp in PNG metadata. Same visual content, different bytes.
The fix: add metadata={'CreationDate': None} to remove non-deterministic elements. Now the test passes.
This is the value of designing explicit counterfactual tests. Without hash comparison, a subtle bug (wrong file path, missing data, changed parameter) might go unnoticed until much later.
Time Investment
| Task | Time |
|---|---|
| Dependency analysis | 20 min |
| Reorganization planning | 15 min |
| File operations and import updates | 30 min |
| Counterfactual testing | 25 min |
| Documentation generation | 15 min |
| Total | 1 hr 45 min |
Manual dependency tracing across 47 files alone would likely exceed this total time investment.
How to Cite This Research
Too Early To Say. "47 Scripts to 15: Cleaning a Research Codebase." November 2025. https://tooearlytosay.com/research/methodology/cleaning-research-codebase/Copy citation