In AI-assisted research, a stale memory entry can put a wrong number in a published paper, and from there into a policy brief, a funding formula, or an eligibility cutoff that affects real people years after the analysis is forgotten. The infrastructure accumulates fast: Skills that format tables for a specific journal. Agents that pull data from a federal API and validate it. Hooks that block a document from compiling until every figure has descriptive alt text. Memory entries that say “always handle this data file using method X” because method Y failed six months ago. (The Medicaid fraud detection pipeline behind our recent series accumulated enough of all four to illustrate every failure mode below.)
Why this fails differently in research
Stale numbers do not stay on the page. Health, education, and food-policy papers feed eligibility cutoffs, funding formulas, and program evaluations within months of publication. A wrong coefficient in a published table can become a wrong threshold in a regulation, then a wrong eligibility decision for a household.
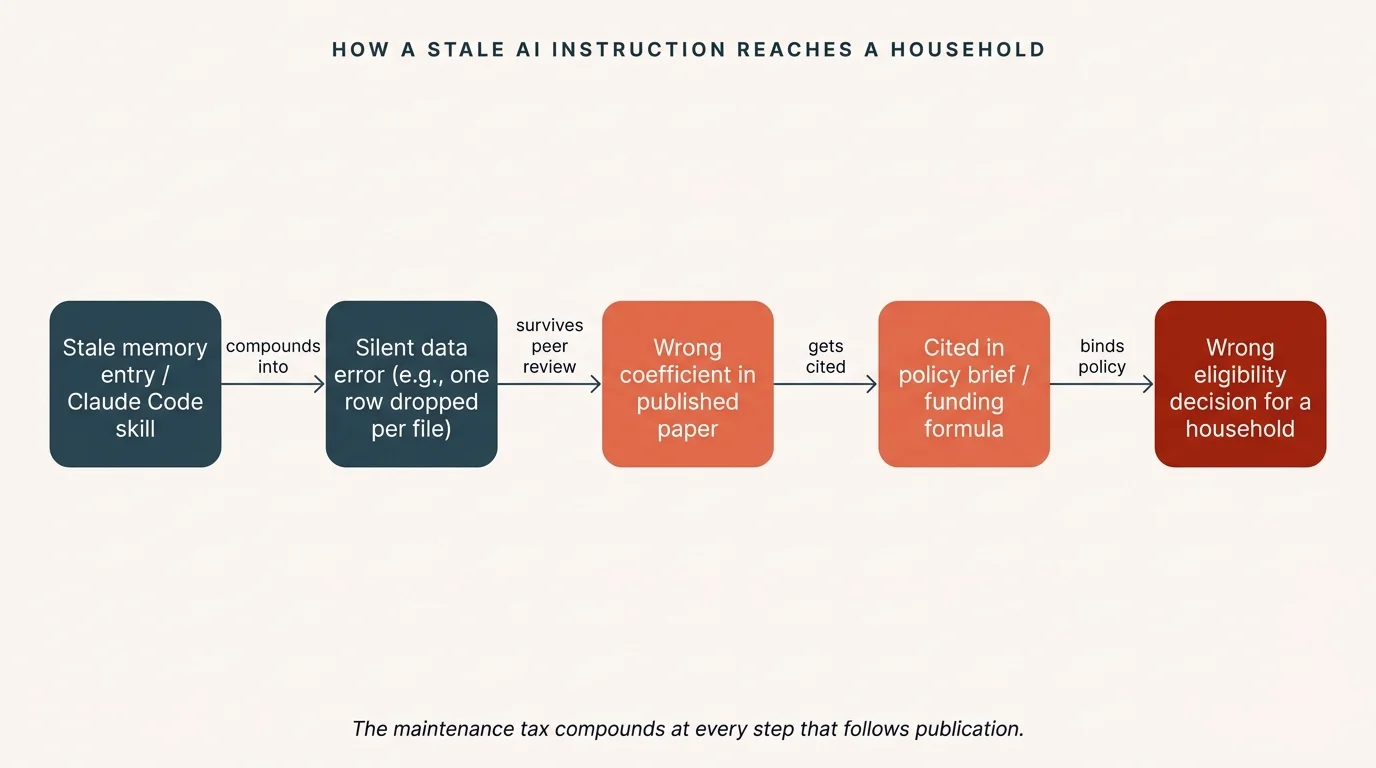
The maintenance tax compounds at every step that follows publication.
In software engineering, a stale skill mostly costs time. In empirical research, it produces incorrect results that look reasonable. Consider a memory entry that says “the Census API returns malformed county codes for California; always strip the leading zero before merging.” That instruction was accurate in January, when a specific API endpoint had a known formatting issue. Census fixed the endpoint in March. The memory entry persists, and now every California merge strips, without warning, a character that should be there. The county codes still merge, but a handful match to the wrong county. The regression runs. The coefficients come out. Nobody catches the error because the pipeline “works.”
Or consider a skill that drops the first two header rows from Bureau of Labor Statistics (BLS) employment files because the 2024 download included two metadata lines. The 2025 format has one. The skill still drops two rows, quietly discarding the first observation in every file, and the sample sizes in the paper are all off by one per source file.
Both errors survive peer review because they are internally consistent: the pipeline produces output, the output looks reasonable, and the error hides in an instruction nobody re-examined because it “worked last time.” (For a related case of how small processing decisions compound, see how a 49% mismatch rate dropped to 12% once the underlying assumptions were re-examined.)
The dumbest model available
The model available today is the least capable version that will ever be available. As Sam Altman put it at Stanford in May 2024, “GPT-4 is the dumbest model any of you will ever have to use again, by a lot.” Every capability gap a skill compensates for today will likely be filled by the model itself within a few quarterly releases: the citation-formatting skill, the accessibility-tag hook, the structured literature-search agent.
Each skill is therefore a patch with an expiration date set by the next model release. A skill becomes actively harmful, rather than merely stale, the moment its output diverges from what the bare model would produce on the same input: at that point it is overriding a more capable model with an outdated instruction, and the gap between what the model can do and what the infrastructure allows it to do widens with every release.
Evaluating skills with benchmarks, not vibes
The instinct is to assess skills informally: “it seems to work.” The problem is that “seems to work” does not survive a model update, and in research, “seems to work” is exactly how wrong numbers come out looking right.
A more rigorous approach uses the same logic that applies to empirical research: define a testable claim, run the experiment, compare to a baseline.
Step 1: Define assertions. Each skill should have a set of concrete, checkable outcomes. For an accessibility compliance skill, the assertions are specific: the output document must have a tagged structure, all figures must have alt text, all table header cells must be marked as headers.
For a data-cleaning skill, the assertions are empirical: the output file must have the expected number of rows, the merge key must be unique, the value range must fall within documented bounds. A prompt to generate assertions for an existing skill:
Read the skill file at [path]. List every concrete,
testable outcome this skill is supposed to produce.
For each outcome, write a check that returns pass/fail.
Flag any outcome that depends on assumptions about
the data format or model behavior that might have
changed since the skill was written.
Step 2: Compare skill output to bare-model output. The key test: does the skill still add value over what the model does on its own?
I'm going to give the same task twice. First, handle
it using only these instructions (no skill). Then I'll
run the skill on the same input. Compare the two
outputs and note any differences. Flag cases where
the skill produces worse output than the plain prompt.
If the outputs are equivalent, the skill’s value was in compensating for a limitation the model has since outgrown. If the skill produces worse output (enforcing an outdated format, applying a correction that is no longer needed), it is actively harmful and should be retired immediately.
Step 3: Track correction rates over time. For skills that do add value, track how often they trigger changes.
Look at the last 5 times this skill was run. How many
corrections or changes did it make each time? What is
the trend? If it is consistently catching fewer than 2
issues per run, flag it for review. If it caught zero
on the last 3 runs, flag it for retirement.
An editing skill might catch an average of eight corrections per document when first deployed. Four months later, the average drops to two. The model internalized the patterns. If the count hits zero consistently, the skill has become overhead.
Fixing stale triggers
Skills activate based on trigger descriptions: keywords and phrases that tell the assistant when to invoke them. As projects and data sources evolve, those triggers drift in two directions.
False negatives mean the skill does not fire when it should. A slide-building skill triggers on “branded presentation” and “department slides.” But when a colleague asks for “a deck for the advisory board,” the skill does not fire because “deck” and “advisory board” are absent from the trigger list.
False positives mean the skill fires when it should not. A data-pipeline skill triggers on “pull economic data” and “download federal statistics.” It also triggers on “fetch the data,” which is broad enough to fire when working with a local spreadsheet that has nothing to do with federal APIs.
Testing triggers is straightforward. For a slide-building skill, the test set might look like this:
Should activate:
Make me a presentation for the advisory board meeting
Build a deck summarizing the Q2 findings
Create slides for the department retreat
Put together a PowerPoint for the grant review
Draft a slide deck on the pilot program results
Should NOT activate:
Summarize the advisory board meeting notes
Write a memo about the Q2 findings
Create a one-page brief for the department
Draft a report for the grant review
Write up the pilot program results
Running all ten through the assistant and checking which ones trigger the skill reveals gaps in both directions.
Maintenance and reproducibility
Published research adds a wrinkle: the infrastructure that produced the results needs to be stable and documented at publication time, even as it keeps evolving for future work. A reproducibility package that includes skill files and memory entries is a snapshot of a specific model-plus-infrastructure configuration, and the maintenance cycle should not retroactively alter the infrastructure behind published results.
The practical approach borrows from Sandve et al.’s Ten Simple Rules for Reproducible Computational Research (PLOS Comput Biol, 2013): tag or archive the skill and memory state at submission time (a git tag works), then continue evolving the working infrastructure. If a reviewer asks to replicate a finding, the tagged version reproduces the exact pipeline. The current version reflects the latest model capabilities.
This creates a clean separation between “what produced this result” (frozen) and “what produces the best result going forward” (evolving). Without that separation, maintaining infrastructure for new work risks breaking the trail back to published work.
A maintenance cycle
A quarterly cycle works well for most research workflows. The protocol has six steps: audit by invocation frequency, benchmark high-use skills against the bare model, test triggers in both directions, prune memory entries whose underlying reason no longer applies, consolidate overlapping skills, and retire hooks the model has outgrown.
Audit by invocation frequency. Pull the list of all skills. Flag any skill uninvoked for 60 days. If the workflow it encodes is still valuable, the model may be handling it natively now.
Benchmark high-use skills against the bare model. For skills invoked weekly or more, run them against the model on three to five representative tasks without the skill loaded. Compare outputs.
Test triggers on fresh prompts. Five prompts that should activate the skill, five that should not. Check both directions.
Prune memory entries. A prompt to audit them:
Read MEMORY.md and every memory file it references.
For each entry, check: (1) does the file or behavior
it references still exist? (2) is the "why" reason
still valid? (3) is it older than 90 days without
being updated? Flag any entry where the answer to
all three is no, or where the referenced file/tool
no longer exists.
Consolidate overlapping skills. A prompt to find candidates:
Read every skill file in the skills directory. Group
them by what they do. Flag any group where two or more
skills have overlapping trigger descriptions or produce
similar outputs. For each overlap, suggest how to merge
them into a single skill with a mode parameter.
Treat hooks as temporary. A hook that blocks document compilation without alt text on every figure exists because someone once forgot alt text. Once the model reliably includes alt text without the hook, the enforcement becomes overhead.
The compound return
Maintaining the infrastructure is how a research workflow stays aligned with the best available model. Each maintenance cycle is a chance to shed weight, absorb new model capabilities, and let the assistant do what it now does well without inheriting yesterday’s patches.
Trusting the processes we built means reassessing them systematically and regularly. The cheapest audit is the one we run before our published table walks into someone else’s eligibility formula.
Cite this article
Cholette, V. (2026, May 21). claude Code Skills Get Stale. Audit Them Quarterly.. Too Early To Say. https://tooearlytosay.com/research/methodology/claude-code-skills-stale-audit/